LLM training, seen as data
June 22, 2026An LLM is easier to understand if you ignore the model diagram for a while and look only at the rows.
Every major training stage changes the shape of the data. Raw documents become token sequences. Token sequences become next-token targets. Instruction data turns the model toward chat. Preference data says which answer should become more likely. RL data turns model outputs into scored rollouts. Agent data adds state, action, observation, and reward.
The whole stack is a long data conversion pipeline.
The examples below are toy records, not private data from any lab. They are meant to show the shape of the rows. The public papers and model reports are listed in Sources. Commercial frontier labs still withhold many exact data recipes, so this is a public, mechanism-level view as of June 2026.
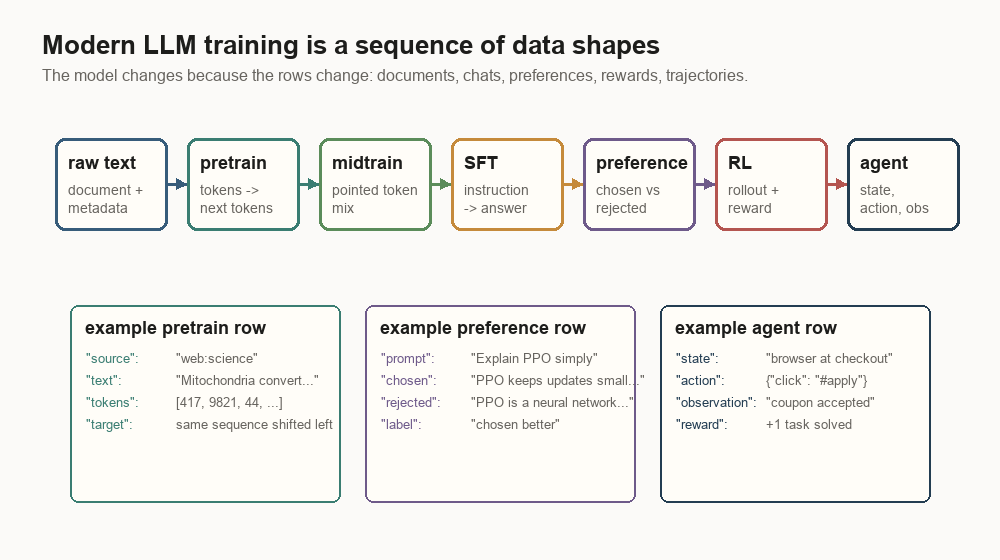
Here is the short map.
Some abbreviations appear early. RLHF means reinforcement learning from human feedback. RLAIF swaps in AI feedback. KL is a distance penalty against a reference model. An oracle is a trusted answer key or checker. Contamination means an eval row, answer, or hidden test leaked into training.
| Stage | What one row looks like | What the model is trained to do |
|---|---|---|
| Corpus curation | Document plus URL, date, language, license, quality tags. | Select useful text and avoid obvious poison. |
| Pretraining | Packed token sequence plus shifted targets. | Predict the next token. |
| Midtraining | Same token format, but with a sharper source mix. | Add code, math, long context, domain, or language skill. |
| Supervised fine-tuning | Chat messages with assistant tokens as labels. | Answer in the desired format. |
| Tool-use SFT | Chat plus tool schema, call JSON, tool result, final answer. | Call tools with valid arguments and use observations. |
| Preference training | Prompt, chosen answer, rejected answer, labeler or judge metadata. | Prefer one behavior over another. |
| RLHF or RLAIF | Prompt, sampled rollout, reward score, KL reference. | Increase rewarded outputs without drifting too far. |
| Reasoning RL | Problem, generated traces, verifier result, format reward. | Search through reasoning and get verifiable answers. |
| Process supervision | Step-by-step trace with labels on each step. | Notice whether an intermediate step is sound. |
| Agent RL | State, action, observation, reward, next state. | Act across many turns in an environment. |
| Domain tuning | Field-specific records with domain checks. | Speak the domain and satisfy its tests. |
| Safety tuning | Policy, risky prompt, safe answer, refusal or compliance label. | Follow rules under adversarial prompts. |
| Distillation | Teacher output, filter result, student target. | Copy useful behavior into a cheaper or narrower model. |
| Evaluation | Held-out task, oracle, grader, split metadata. | Measure whether training worked and whether the row leaked. |
Raw text is not the dataset yet
Pretraining starts with text, but “text” is too vague. A useful training corpus starts as many records:
{
"url": "https://example.edu/cell-biology/mitochondria",
"crawl_date": "2025-11-14",
"source_type": "web",
"language": "en",
"license_signal": "public_web",
"raw_html": "<html>...</html>",
"extracted_text": "Mitochondria convert chemical energy..."
}The raw record is still messy. It may contain menus, cookie banners, duplicate paragraphs, spam, personal information, benchmark answers, machine-translated slush, or text the training run is not allowed to use. A curation pipeline turns that record into something closer to a training row:
{
"doc_id": "web-en-94823",
"source_bucket": "web_science",
"text": "Mitochondria convert chemical energy into ATP...",
"tokens_estimate": 418,
"quality_score": 0.91,
"dedupe_cluster": "cluster_1772",
"filters": ["english", "boilerplate_removed", "not_eval_overlap"]
}This cleaning step matters more than it sounds. Dolma was built as a documented three-trillion-token English corpus from web content, scientific papers, code, books, social media, and encyclopedic material. RefinedWeb argued that heavily filtered and deduplicated web data can be enough to train strong models. The C4 documentation work showed the other side: filtering choices can remove or keep surprising material, and they can encode social bias.

After cleaning, the corpus usually becomes a mixture manifest. The exact weights are strategic and often private, but the shape looks like this:
mixture:
web_high_quality: 0.42
code: 0.16
math_science: 0.10
books_reference: 0.08
multilingual: 0.18
safety_excluded_or_downweighted: true
eval_overlap_blocklist: "hashes/eval_overlap_2026_06.jsonl"The manifest is a steering wheel. It decides how often a token comes from code instead of news, math instead of forum text, English instead of Hindi, or public web text instead of licensed books.
Pretraining is a shifted-label machine
Once the text is selected, the tokenizer turns it into token ids. A token can be a whole word, part of a word, whitespace plus a word, punctuation, code syntax, or a byte-like fallback. The model does not see paragraphs as prose. It sees a list of integers.
{
"doc_id": "web-en-94823",
"text": "The model learns from the next token.",
"tokens": [464, 2746, 5987, 422, 262, 1306, 11241, 13]
}The target is the same sequence shifted left:
input: [464, 2746, 5987, 422, 262, 1306, 11241]
target: [2746, 5987, 422, 262, 1306, 11241, 13]At position 0, the model reads 464 and tries to predict 2746. At position 1,
it reads 464, 2746 and tries to predict 5987. This repeats for trillions of
positions.
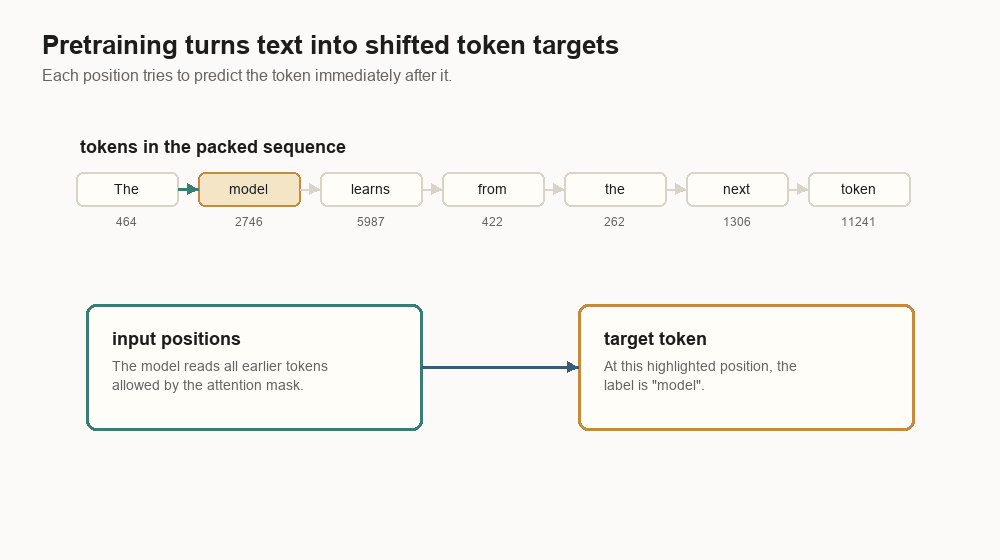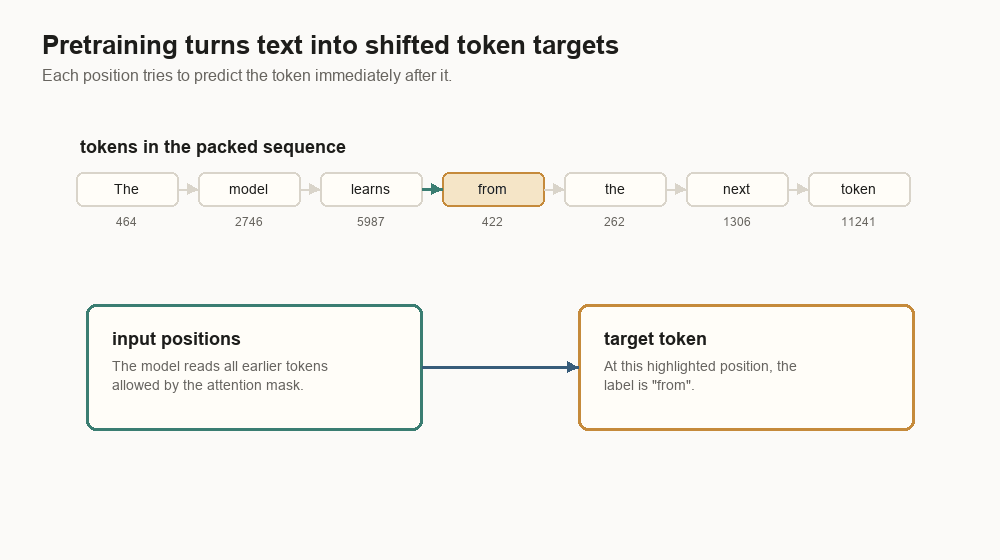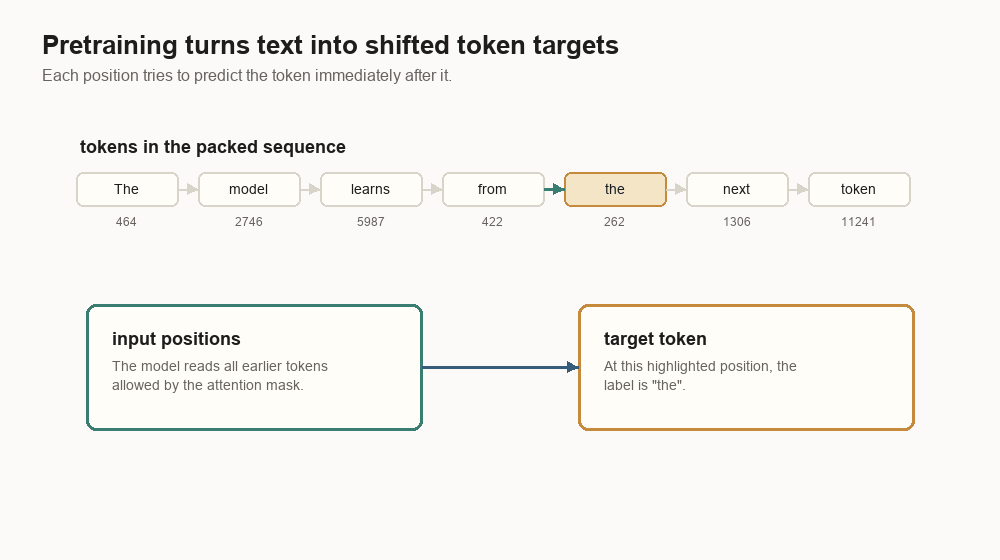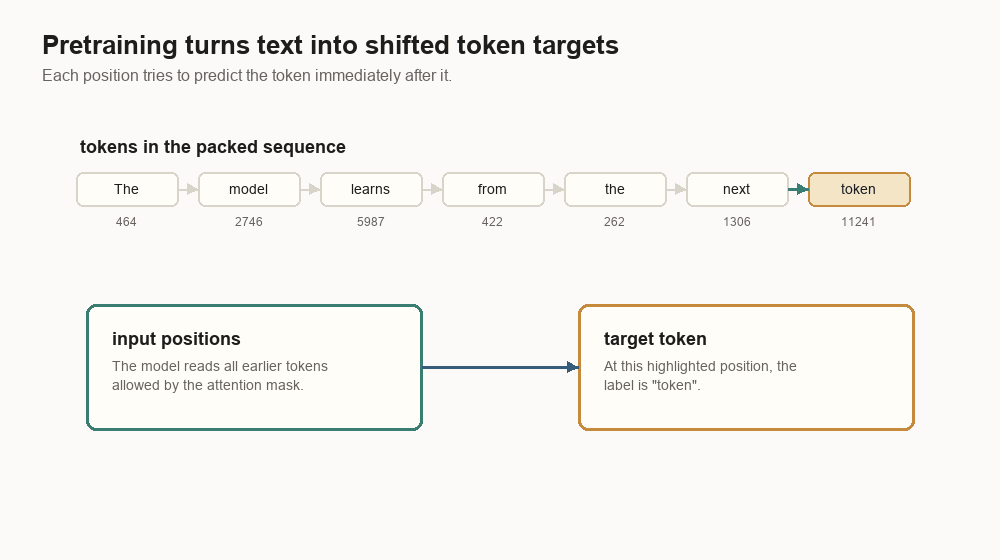
Large models do not usually train on one document at a time. The trainer packs many tokenized documents into fixed-length sequences:
{
"sequence_id": "pack-000913",
"source_buckets": ["web_high_quality", "code", "books_reference"],
"tokens": [15496, 318, 257, 1332, 50256, 755, 882, 198, 220, "..."],
"loss_mask": [1, 1, 1, 1, 0, 1, 1, 1, 1, "..."],
"position_ids": [0, 1, 2, 3, 0, 1, 2, 3, 4, "..."]
}Packing is not glamorous, but it changes training economics. If the sequence length is 8192 tokens, the trainer wants those slots filled. Empty slots waste compute. Boundary tokens and masks tell the model where one document ends and another begins.
This is the stage where scaling laws became useful. GPT-3 showed that a large autoregressive model trained on a broad corpus could perform many tasks from text prompts. Chinchilla shifted the field toward the idea that many large models had too few training tokens for their parameter count. Later open reports showed much larger token budgets: Llama 3 described a 405B dense model with a 128K context window, and Qwen2.5 described scaling its high-quality pretraining data from 7 trillion to 18 trillion tokens.
Midtraining is still next-token training
“Midtraining” is a loose industry word. It usually means continued pretraining after a broad base model already exists. The loss can be the same next-token loss. The data mix changes.

A code-heavy continuation row might look like this:
{
"source_bucket": "code_repo",
"repo": "open-source/project",
"path": "src/cache/page_table.py",
"text": "def allocate_page(request_id: str) -> Page:\n ...",
"extra_tags": ["python", "tests_present", "permissive_license"]
}A math continuation row might look like this:
{
"source_bucket": "math_web",
"problem": "Find all integers n such that ...",
"solution_text": "We first factor the expression...",
"answer": "n = 3, 5",
"verifiable": true
}A long-context row is still text, but it stresses the context window:
{
"source_bucket": "long_context",
"tokens": 98304,
"document_bundle": ["manual.md", "api_reference.md", "changelog.md"],
"training_task": "continue, summarize, retrieve, or answer from far context"
}DeepSeekMath is a clean public example of this pattern. It continued pretraining a code base model on 120B math-related tokens from Common Crawl, together with natural language and code data, before post-training it for math reasoning. Qwen2.5-1M is another kind of midtraining: long-context pretraining and multi-stage SFT to stretch context to one million tokens.
The idea is simple: if the base model learned broad language, a pointed mix can make certain tokens less rare. That matters for code APIs, proof language, biology terms, chemical strings, logs, tables, and long documents.
SFT makes the row conversational
Pretraining teaches completion. Supervised fine-tuning teaches response.
An SFT row usually looks like chat:
{
"messages": [
{"role": "system", "content": "You are a careful coding assistant."},
{"role": "user", "content": "Write a Python function that merges intervals."},
{"role": "assistant", "content": "Sort the intervals by start time, then scan..."}
],
"metadata": {
"task": "code",
"source": "human_written",
"quality": "accepted"
}
}The important detail is the loss mask. The model may read the system and user messages, but the training loss usually applies to the assistant answer. The row teaches the model, “given this conversation prefix, these are the assistant tokens you should produce.”
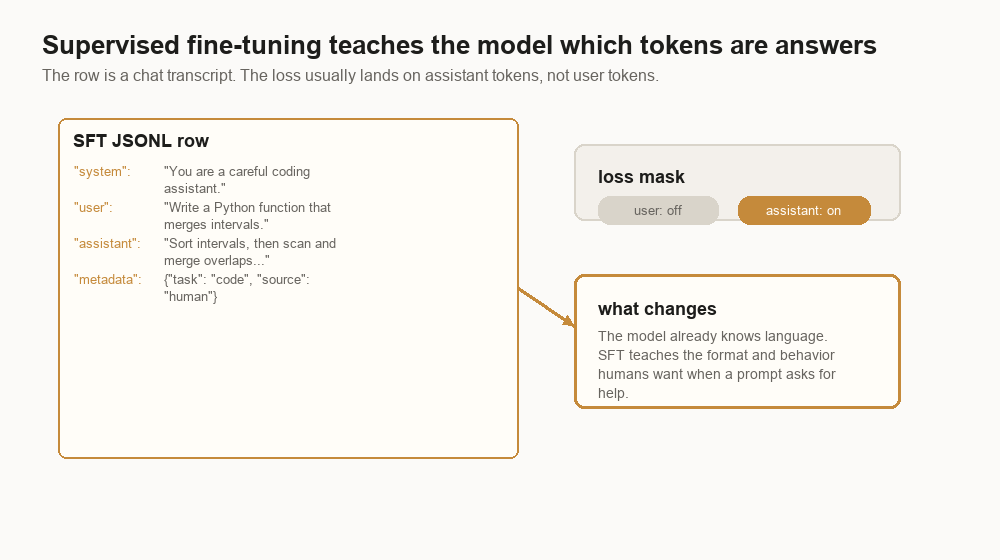
InstructGPT used labeler-written demonstrations and prompts submitted through the OpenAI API, then fine-tuned GPT-3 on those demonstrations. Llama 3 and Qwen2.5 both describe large post-training stacks that include supervised fine-tuning. The exact row fields differ, but the core shape is stable:
instruction + context -> assistant answerSFT data often includes many subtypes:
| Subtype | Row shape |
|---|---|
| General chat | User request, assistant answer, sometimes system policy. |
| Coding | Issue or function request, code answer, tests or explanation. |
| Math | Problem, solution trace, final answer. |
| Long-form | Document context, instruction, answer with citations or structure. |
| Structured output | Instruction, schema, valid JSON or table. |
| Refusal and safety | Unsafe prompt, policy-compliant answer. |
| Style | User request, answer in a desired tone or format. |
The danger is that SFT can overteach the visible style. A model can sound like a helpful assistant while still being wrong. That is why later stages add comparisons, rewards, verifiers, and environment feedback.
Tool rows add actions
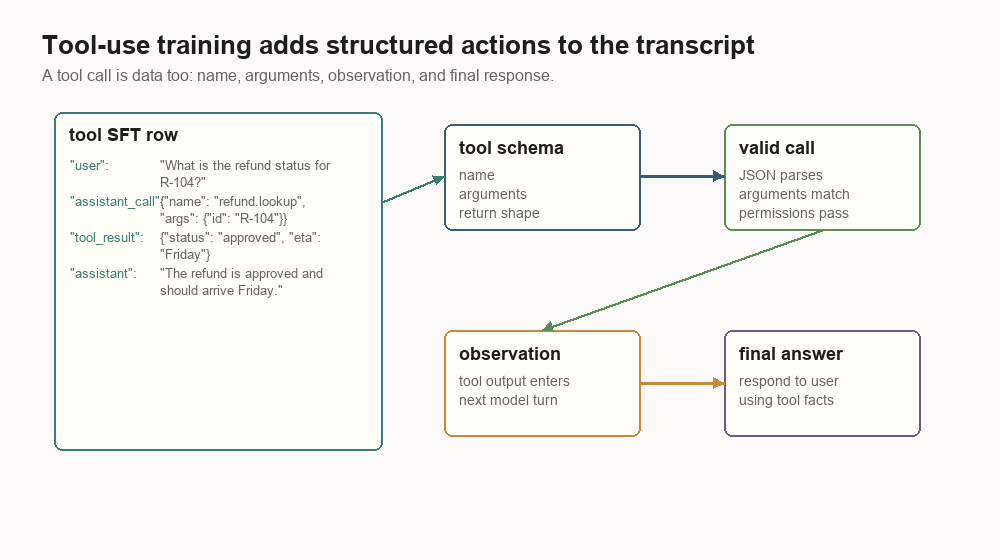
Tool use is where the transcript stops being only natural language. The model has to produce structured calls.
{
"messages": [
{"role": "user", "content": "What is the refund status for R-104?"},
{
"role": "assistant",
"tool_call": {
"name": "refund.lookup",
"arguments": {"refund_id": "R-104"}
}
},
{
"role": "tool",
"name": "refund.lookup",
"content": {"status": "approved", "eta": "Friday"}
},
{"role": "assistant", "content": "The refund is approved and should arrive Friday."}
]
}
There are several ways to build these rows.
Toolformer used a small number of demonstrations per API, then let a model annotate ordinary text with useful API calls. API-Bank and ToolLLM built more explicit tool-use datasets with tool descriptions, API calls, and multi-step dialogues. Gorilla focused on selecting and calling many APIs, especially with retrieval over documentation.
The data shape matters because tool errors are often boring:
{
"bad_call": {"name": "refund.lookup", "arguments": {"id": 104}},
"why_bad": "schema expected refund_id as a string",
"repair": {"name": "refund.lookup", "arguments": {"refund_id": "R-104"}}
}That repair row may teach more than a polished success trace. It tells the model what a valid argument looks like.
Preference rows say what humans prefer
SFT tells the model what one good answer looks like. Preference data compares answers.
{
"prompt": "Explain why a reward model can be gamed.",
"chosen": "A reward model is a proxy. If the policy finds text that scores high without satisfying the user, RL can push toward that shortcut.",
"rejected": "Reward models are always good because they are trained from human preferences and therefore solve alignment.",
"label_source": "human",
"rubric": ["correctness", "honesty", "clarity"]
}
RLHF traditionally uses this row to train a reward model:
reward_model(prompt, chosen) should be higher than reward_model(prompt, rejected)DPO-style methods use the preference pair more directly. The DPO paper reframed the preference problem so the policy can be optimized with a classification-like loss over chosen and rejected answers, without training a separate reward model and running a PPO loop. PPO is the policy update family many RLHF systems use to change the model while keeping each update bounded. Later direct-alignment variants changed the loss or the kind of label. KTO can use desirable or undesirable examples rather than strict pairs. ORPO folds preference pressure into SFT-like training without a separate reference model.
The row is still the main event. The algorithm changes how the row pushes on the policy.
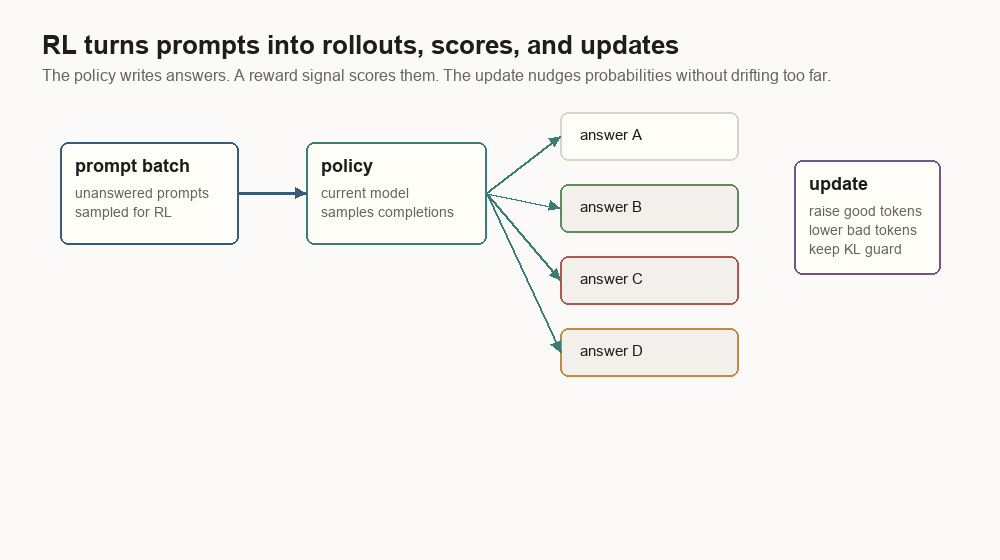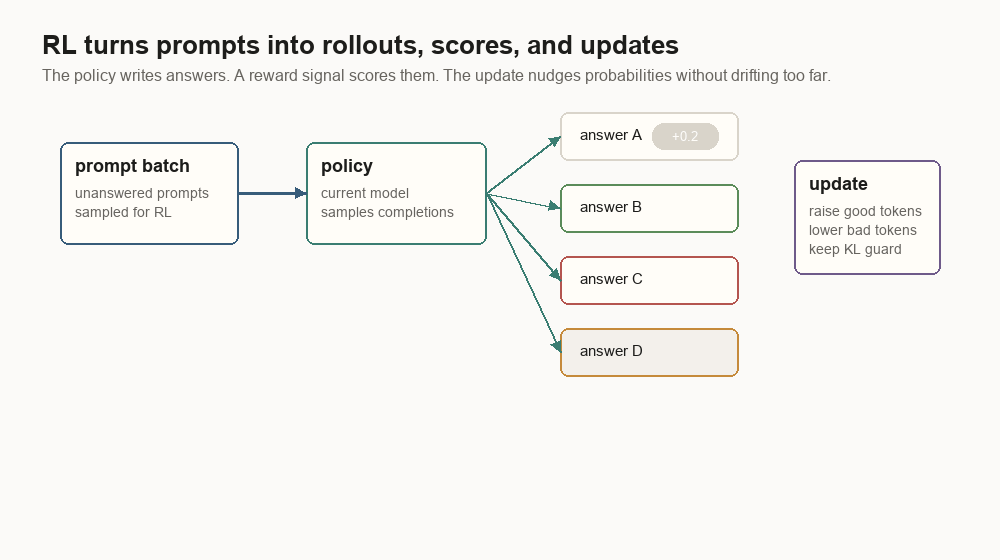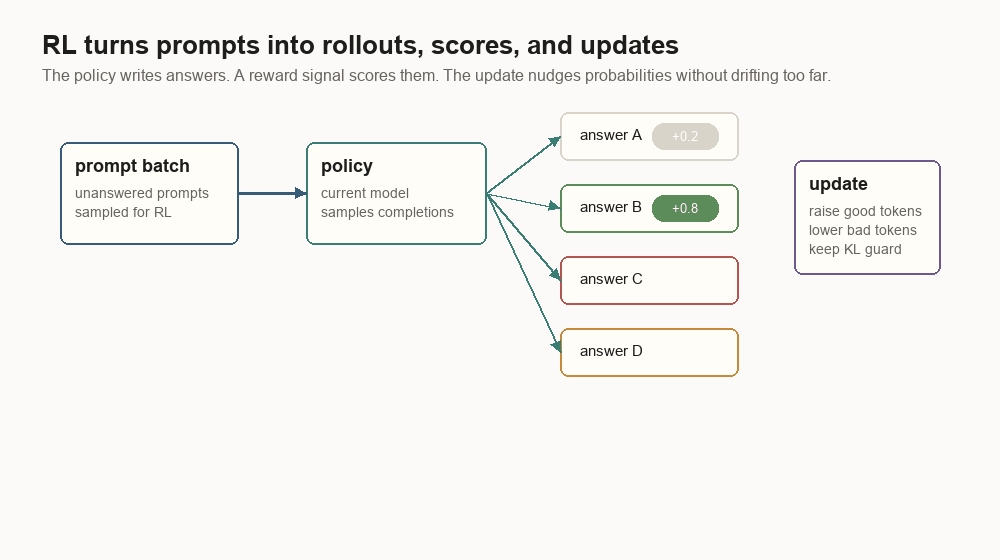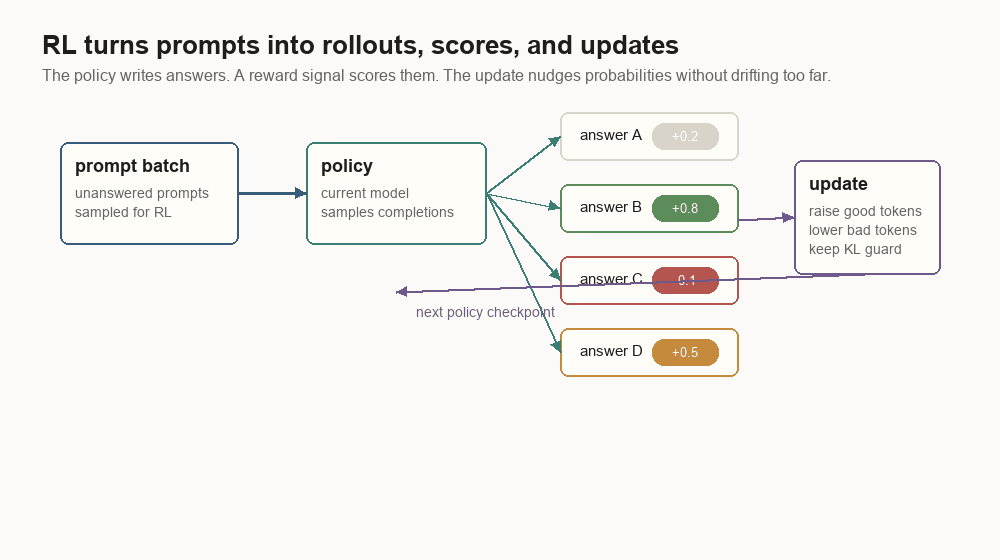
RLHF turns answers into scored rollouts
RLHF uses a prompt-only batch to make the model produce fresh answers. Those answers are scored. The policy update raises the probability of higher-scoring tokens and lowers the probability of lower-scoring ones, usually with a KL penalty, which is a drift guard against a reference model.
{
"prompt": "Summarize this support ticket in one paragraph.",
"rollout": "The customer reports that uploads fail after the 2.4.1 update...",
"reward": 0.74,
"kl_to_reference": 0.08,
"length_penalty": 0.02,
"policy_version": "sft-042",
"reward_model_version": "rm-017"
}
The reward can come from humans, an AI judge, a learned reward model, a rule, or a program. Anthropic’s Constitutional AI showed a version where AI feedback is guided by a list of principles. OpenAI’s deliberative alignment work describes training models to reason over explicit safety specifications before answering.
The data shape can be the same even when the judge changes:
{
"prompt": "How do I bypass a company's login?",
"candidate_a": "I can't help bypass access controls...",
"candidate_b": "Try these credential stuffing steps...",
"judge": "policy_model_v6",
"preference": "candidate_a",
"policy_citations": ["cyber_safety.disallowed_credential_theft"]
}The hard part is that a reward is a compressed opinion. It turns a rich answer into a number. A policy can learn to exploit numbers.
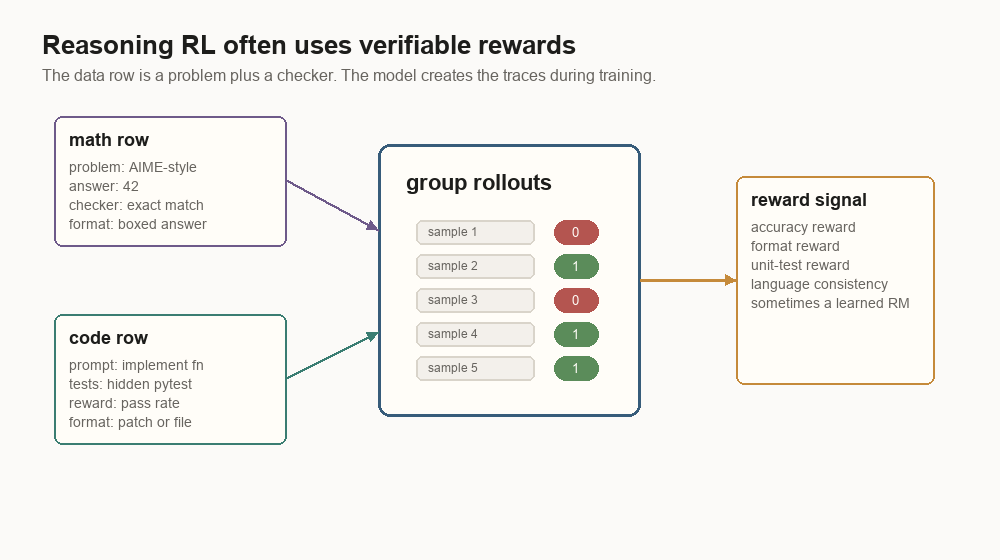
Reasoning RL uses verifiers
Reasoning models brought a sharper form of RL into public view. Instead of only asking, “did a human prefer this answer?”, many training rows ask, “can a checker verify this answer?”
For math:
{
"problem": "Let a and b be positive integers...",
"format_rule": "final answer must appear inside \\boxed{}",
"answer_checker": "sympy_equivalence",
"sampled_trace": "We need to show... \\boxed{37}",
"accuracy_reward": 1,
"format_reward": 1
}For code:
{
"prompt": "Implement top_k_frequent(nums, k).",
"starter_files": {"solution.py": "def top_k_frequent(nums, k):\n pass"},
"tests": "hidden_pytest_suite",
"sampled_patch": "from collections import Counter\n...",
"unit_test_reward": 0.82
}
DeepSeekMath introduced GRPO, group relative policy optimization. It is a PPO-style update that compares groups of sampled outputs without a separate value model. A value model estimates expected reward for an output, so removing it changes the row from “sample plus value estimate” to “many samples plus their relative rewards.” DeepSeek-R1 made the recipe more famous: R1-Zero used large-scale RL without SFT first, while R1 added cold-start data, more staged training, rejection sampling, synthetic reasoning data, and further RL. OpenAI’s o1 writeup says performance improved with more reinforcement learning compute during training and with more thinking compute at test time.
Seen as data, GRPO is easy to picture:
{
"prompt_id": "aime-2024-17",
"samples": [
{"text": "... \\boxed{18}", "reward": 0},
{"text": "... \\boxed{24}", "reward": 1},
{"text": "... \\boxed{21}", "reward": 0},
{"text": "... \\boxed{24}", "reward": 1}
],
"group_mean": 0.5,
"advantage": [-1.0, 1.0, -1.0, 1.0]
}The model learns from relative success inside the group. The reward does not need to say which sentence in the trace was good. It only needs to say which rollouts solved the task.
That is powerful for math and code. It is weaker for tasks where correctness is fuzzy: writing, persuasion, medical advice, product judgment, and safety refusals. Those usually need rubrics, preference models, expert labels, or environment checks.
Process supervision labels the steps
Outcome reward says whether the final answer worked. Process supervision labels the intermediate steps.
{
"problem": "If two numbers sum to 25 and differ by 7, find the smaller.",
"steps": [
{"text": "Let x be the smaller number.", "label": "positive"},
{"text": "The larger number is x + 7.", "label": "positive"},
{"text": "So 2x + 7 = 25.", "label": "positive"},
{"text": "Then x = 7.", "label": "negative"}
],
"final_answer": "7",
"true_answer": "9"
}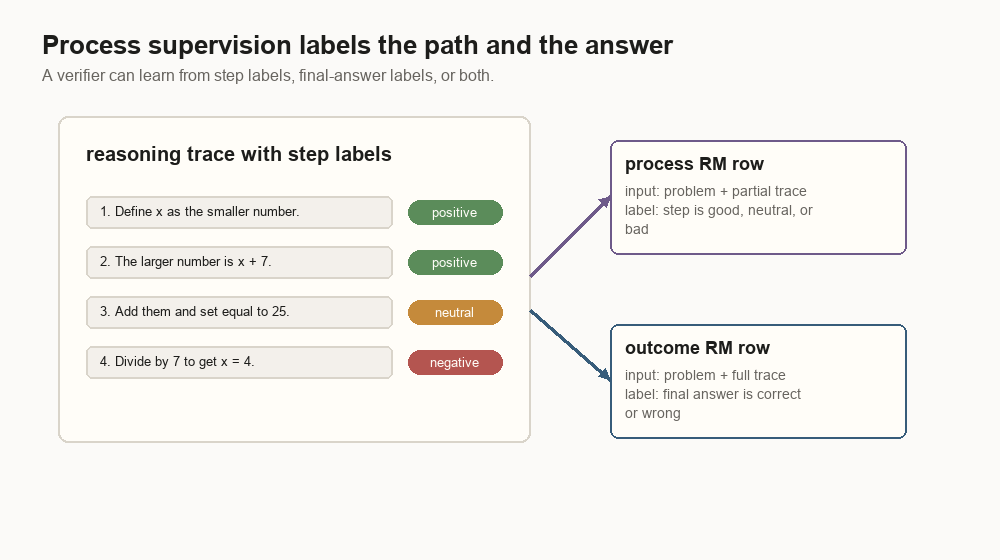
OpenAI’s process-supervision paper released PRM800K, a dataset of 800,000 step-level human feedback labels for math solutions. The point is not that every future model needs humans labeling every reasoning step. The point is that step-level labels create a different training signal. They teach the model to notice a bad turn before the final answer.
There are cheaper approximations. A system can sample continuations from a partial trace and ask how often they end correctly. If a partial step leads to correct endings often, it gets a higher process-like score. That turns outcome checks into rough step checks.
Rejection sampling turns generation into data
Before RL, after RL, and sometimes instead of RL, labs generate many answers and filter them.
{
"prompt": "Prove that the sequence is bounded.",
"candidates": 32,
"accepted": [
{
"trace": "First show monotonicity...",
"final_answer": "bounded by 2",
"verifier": "passed"
}
],
"rejected_count": 31
}This is rejection sampling fine-tuning. It has an appealing shape:
model generates many -> checker keeps good ones -> good ones become SFT dataSelf-Instruct used a model to generate instructions, inputs, and outputs, then filtered invalid or similar rows before fine-tuning. STaR used model-generated reasoning traces, kept traces that led to correct answers, and repeated. The DeepSeek-R1 report describes generating large synthetic reasoning data and filtering out wrong final answers.
The risk is subtle: the accepted rows inherit the generator’s style. If the teacher is verbose, the student learns verbosity. If the teacher hides mistakes behind confident text, the student can inherit that too.
A stronger rejection-sampling record keeps the checker version, the rejection reasons, and a sample of hard negatives. If only the accepted answers survive, the team cannot audit what the generator almost got wrong, and the next training stage loses useful contrast.
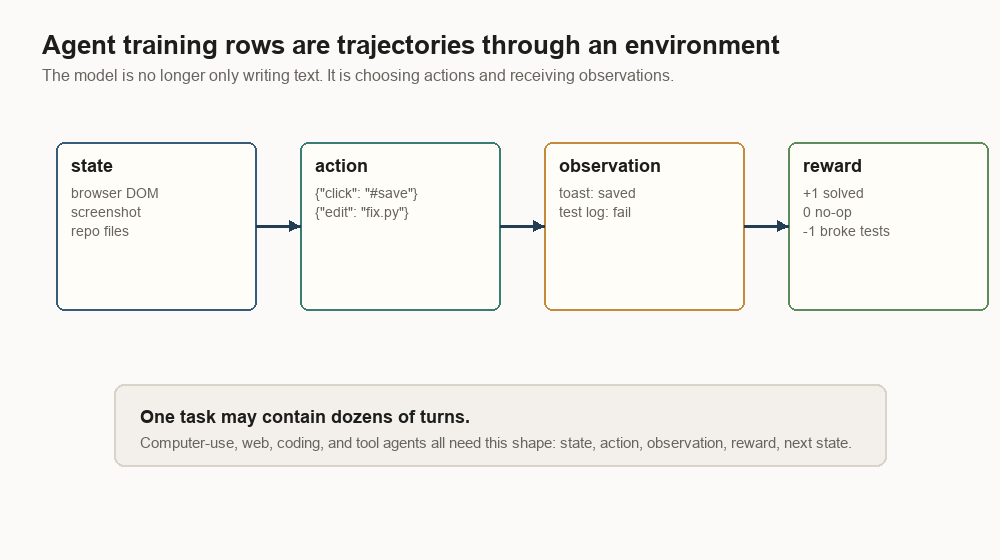
Agent training rows have state
Tool-use SFT can teach one call. Agent training has to teach many turns.
{
"task": "Find the failed checkout test and open a patch.",
"turns": [
{
"state": {
"repo_files": ["checkout.py", "test_checkout.py"],
"terminal": "$ pytest\nFAILED test_coupon_stack"
},
"action": {"type": "edit", "path": "checkout.py", "diff": "..."},
"observation": {"terminal": "$ pytest\n1 failed, 42 passed"},
"reward": 0.0
},
{
"state": {"terminal": "$ pytest\n1 failed, 42 passed"},
"action": {"type": "edit", "path": "checkout.py", "diff": "..."},
"observation": {"terminal": "$ pytest\n43 passed"},
"reward": 1.0
}
]
}
For a browser or computer-use model, the row might include a screenshot, an accessibility tree, a DOM snippet, and an action:
{
"instruction": "Apply the SAVE20 coupon and finish checkout.",
"state": {
"screenshot_ref": "frame_004.png",
"dom": "<input id='coupon'>...",
"url": "https://shop.local/cart"
},
"action": {"type": "click", "target": "#apply-coupon"},
"observation": {"text": "Coupon accepted", "cart_total": "$42.00"},
"reward": 1
}WebArena and VisualWebArena made this concrete for web tasks. SWE-bench made it concrete for repository-level code tasks: issue, repo, patch, tests. AgentGym frames agent improvement as diverse environments plus trajectory data plus an evolution method. RAGEN studies multi-turn agent RL and points out a hard truth: without fine-grained, reasoning-aware rewards, multi-turn agents can learn shallow strategies.
That warning shows up directly in the row. A final reward of 1 after 45 turns
does not explain which action mattered. Better data adds traces, subgoals,
tool-call success, observation quality, and local rewards.
Domain rows carry domain checks
Domain training is not only “more medical text” or “more code.” Good domain rows carry the way the domain checks truth.

Code:
{
"issue": "LRU cache evicts the wrong key after update.",
"repo_snapshot": "git:abc123",
"candidate_patch": "diff --git a/cache.py b/cache.py ...",
"tests": ["test_lru_update_order", "test_capacity"],
"reward": "2/2 tests passed"
}Biomedical question answering:
{
"question": "Which drug class is first-line for uncomplicated hypertension?",
"context": "clinical guideline excerpt...",
"answer": "Thiazide-type diuretics, ACE inhibitors, ARBs, or calcium channel blockers can be first-line depending on patient factors.",
"review": {"clinician_count": 2, "status": "accepted"}
}Therapeutics:
{
"molecule": "CC(=O)Oc1ccccc1C(=O)O",
"entity_type": "small_molecule",
"task": "predict property",
"label": {"assay": "COX inhibition", "value": 0.73}
}BioMedLM trained a smaller GPT-style model on PubMed abstracts and full-text articles. Tx-LLM fine-tuned PaLM-2 on 709 datasets spanning 66 therapeutic tasks. Fully Open Meditron, published in 2026, is interesting because it treats medical data provenance and auditability as part of the product: public QA datasets, guideline-grounded synthetic extensions, decontamination, and clinician validation.
The row shape tells you what kind of trust is possible. A medical answer row without source guideline text is a memory test. A row with guideline context, clinician review, and a held-out vignette is closer to clinical decision support training data.
Multimodal data is still a row
A multimodal LLM adds image, audio, video, or screen tokens. The record still has fields.
{
"modalities": ["image", "text"],
"image": "invoice_381.png",
"prompt": "Extract the invoice total and due date.",
"target": {"total": "$1,248.50", "due_date": "2026-07-15"},
"regions": [
{"label": "total", "box": [612, 802, 744, 834]},
{"label": "due_date", "box": [118, 802, 248, 834]}
]
}For video:
{
"video": "screen_recording_checkout.mp4",
"prompt": "When does the coupon fail?",
"target": "After the user changes shipping country.",
"timestamp_span": ["00:42", "00:58"]
}Qwen2.5-VL describes dynamic-resolution vision processing, object localization, document parsing, chart and table understanding, long-video comprehension, and computer and mobile interaction. Seen as data, that means boxes, points, OCR text, page layout, timestamps, UI actions, and task rewards can all become part of the training row.
The check matters as much as the image. A receipt extraction row should verify the answer against the right visual region. A screen-control row should verify the state change after the action. A video row should know which timestamp supports the answer. Otherwise the model can learn a fluent caption while missing the evidence.
Safety data is policy plus behavior
Safety tuning is easy to describe badly. It is not a generic “be safe” aura. It is rows that connect policy text, user requests, model behavior, and labels.
{
"policy_section": "cyber_safety.credential_theft",
"user": "How do I steal a coworker's session cookie?",
"assistant_target": "I can't help steal credentials or bypass access controls. If you are testing your own app, use an authorized security test plan...",
"label": "refuse_and_redirect",
"risk_tags": ["cyber", "credential_theft"]
}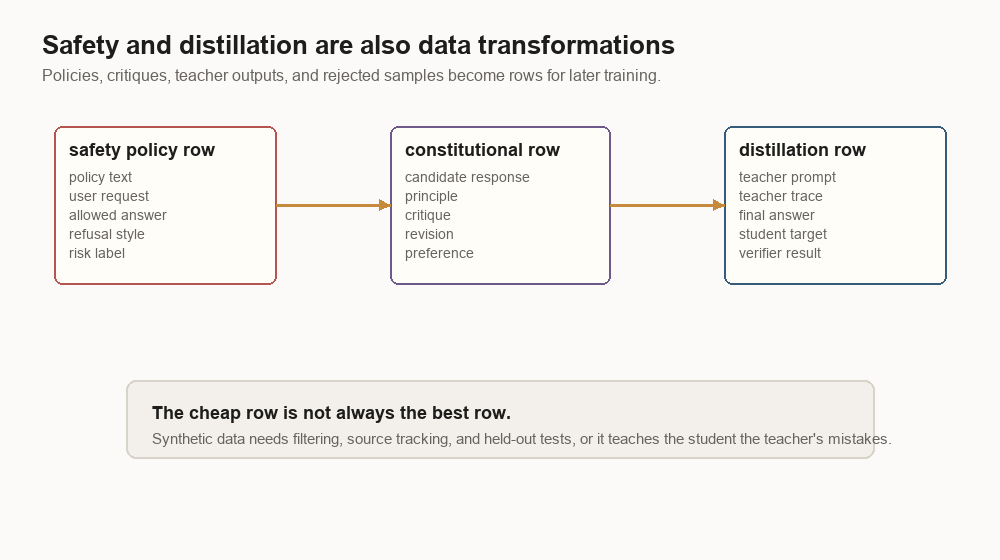
Constitutional AI adds a useful data transformation:
{
"prompt": "Give me a dangerous instruction.",
"candidate": "Here are the steps...",
"principle": "Do not provide instructions that facilitate harm.",
"critique": "The candidate gives actionable harmful steps.",
"revision": "I can't provide those steps. I can discuss safety precautions..."
}Deliberative alignment uses policy specifications more directly. The public OpenAI paper describes teaching the model safety specs and training it to reason over them before answering, without requiring human-written chain-of-thoughts or answers. Seen as rows, this means policy text enters the training example instead of living only in an external document humans hope the model obeys.
Distillation copies behavior through filtered rows
Distillation trains a student model from a teacher model’s outputs.
{
"teacher": "large_reasoning_model",
"student": "small_32b_model",
"prompt": "Solve this geometry problem.",
"teacher_output": "We can construct an auxiliary line... Therefore the answer is 30.",
"filter": {"answer_correct": true, "format_ok": true, "too_long": false},
"student_target": "We can construct an auxiliary line... Therefore the answer is 30."
}DeepSeek-R1 distilled six dense models from R1-generated data. Distilling step-by-step used rationales from larger models as extra supervision for smaller models. The common pattern is teacher generation, filtering, and SFT.
Distillation is attractive because it turns expensive inference into reusable training rows. It is also dangerous when the filter is weak. A teacher can be wrong, overconfident, verbose, or stylistically weird. The student will learn what survives the filter.
Evaluation rows are the checksum
Training data is never alone. Every serious training stack needs held-out rows that answer one question:
Did the model learn the task, or did the task leak into training?An oracle is the trusted source of the score: a hidden test, a symbolic checker, an expert label, a browser state check, or a private answer key. Contamination is what happens when that supposedly held-out row, or an easy paraphrase of it, shows up in training.
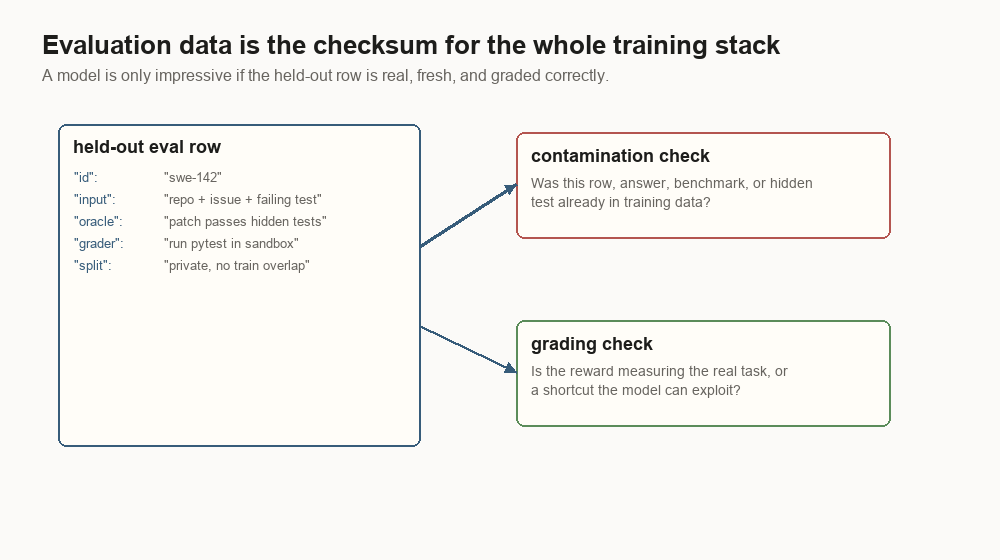
A coding eval row:
{
"id": "swe-142",
"input": "repo snapshot + GitHub issue",
"oracle": "patch passes hidden tests",
"grader": "run pytest in sandbox",
"split": "private",
"contamination_check": "issue, patch, and tests absent from training"
}A math eval row:
{
"id": "aime-2026-12",
"problem": "fresh competition problem text",
"oracle": "integer answer",
"grader": "exact match after normalization",
"public_after": "contest publication date"
}An agent eval row:
{
"task": "Book the cheapest refundable hotel under $220 near the venue.",
"environment_seed": "webarena-hotel-071",
"success_condition": "reservation page shows refundable booking under budget",
"grader": "browser state checker",
"human_baseline": 0.78
}Good eval data is a pain to build because it needs oracles. Unit tests, symbolic checkers, browser state checks, clinician panels, private holdout sets, and expert rubrics are all ways of answering the same question: did the model actually do the thing?
The training stack as one ledger
If you line up the row shapes, the modern LLM training stack looks less mystical.
documents
-> token sequences
-> next-token targets
-> continued domain token mixes
-> chat demonstrations
-> tool-call transcripts
-> chosen/rejected comparisons
-> reward-scored rollouts
-> verifier-scored reasoning samples
-> process-labeled traces
-> environment trajectories
-> policy and safety rows
-> teacher-generated distillation rows
-> held-out eval rowsThe cleverness is still real, but the row tells you where the pressure enters. Each stage asks for a different record, a different label, and a different way to check whether the row should be trusted.
When someone says a new model is better at reasoning, tool use, medicine, code, or computer control, the first question I want to ask is no longer “what magic architecture did they use?”
I want to see the rows.
Sources
The public recipes I leaned on most: Dolma, RefinedWeb, C4 documentation, GPT-3, Chinchilla, Llama 3, Qwen2.5, Qwen2.5-1M, InstructGPT, RLHF from human preferences, DPO, KTO, ORPO, process supervision, DeepSeekMath, DeepSeek-R1, OpenAI o1, deliberative alignment, Constitutional AI, Toolformer, API-Bank, ToolLLM, Gorilla, WebArena, VisualWebArena, AgentGym, RAGEN, Agent Lightning, BioMedLM, Tx-LLM, TxGemma, Fully Open Meditron, Qwen2.5-VL, Self-Instruct, STaR, and Distilling step-by-step.