Evals with Harbor Framework
May 24, 2026I wanted a small test where an agent could look right and still be wrong.
The task was a token billing ledger: a table that turns model usage events into
customer charges. The agent gets provider events, an existing ledger, a rate
card, region multipliers, and ingestion notes. It has to repair the ledger by
writing /app/fix.sql and explain the incident in
/app/incident_report.json.
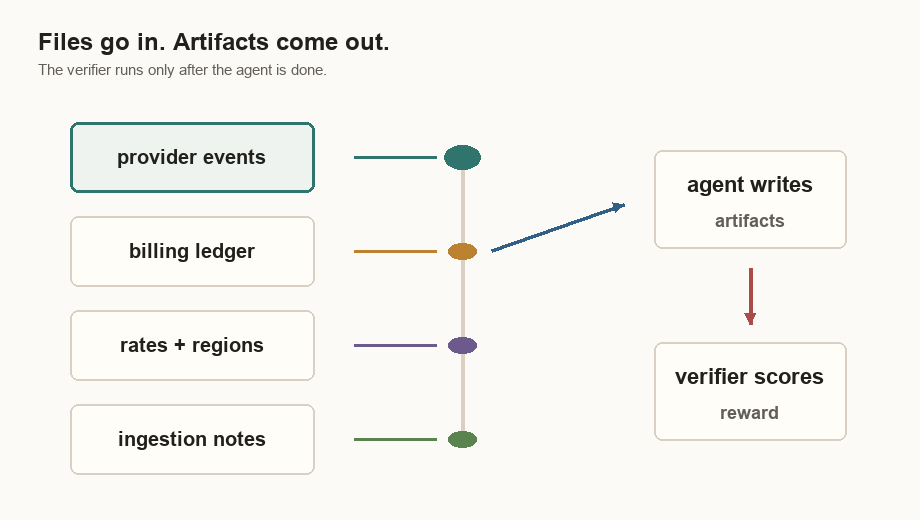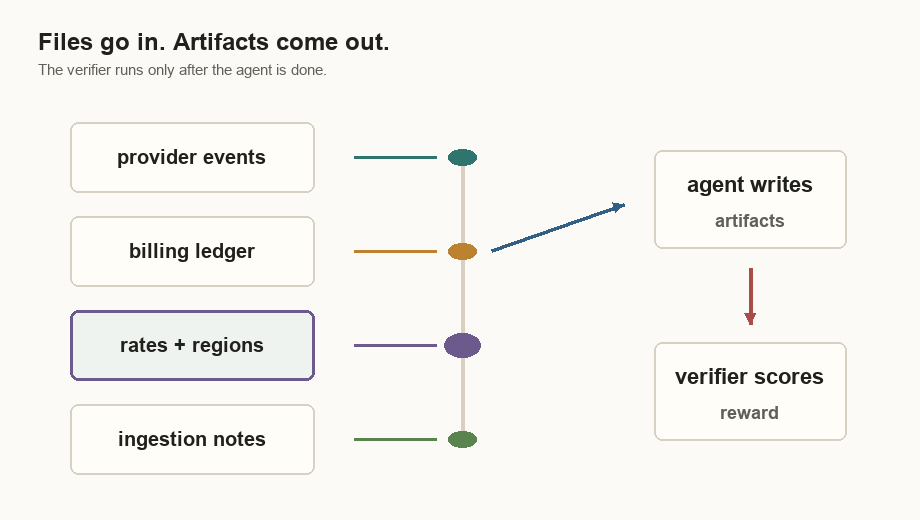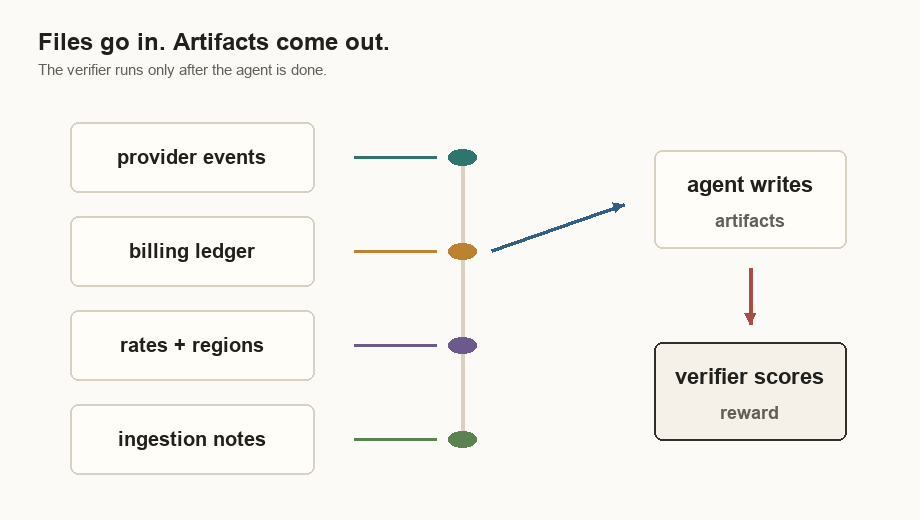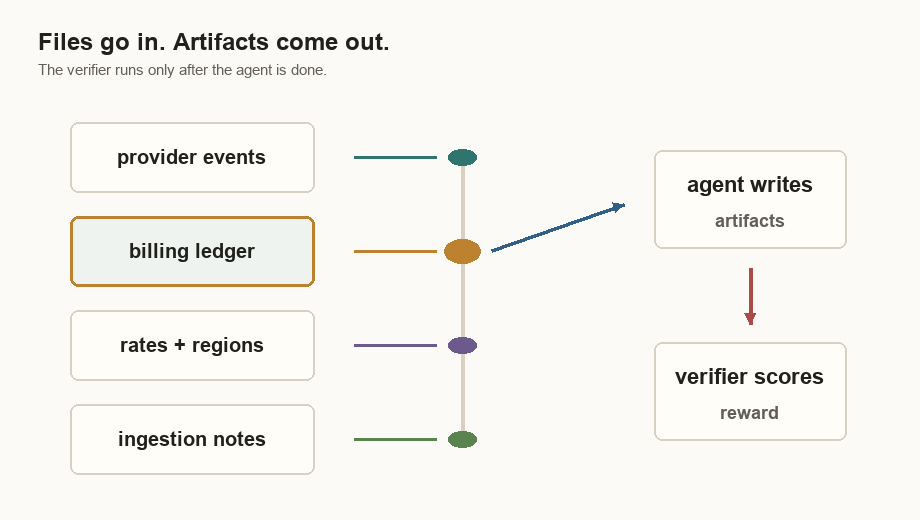
Harbor Framework is the eval harness I used around that task. It puts those files in a sealed environment, runs the agent, keeps the grader hidden until the run is over, and saves the outputs, score, and trace.
That is enough to get started. I explain the Harbor pieces later: what the agent sees, what a task folder contains, how the hidden verifier grades the output, why the oracle run matters, and how artifacts make failures inspectable. First, the bug.
The bug I used for the eval was small but dangerous.
Nothing crashed. No dashboard went red. A billing ledger had sixteen usage events, and five of them were wrong. Four rows stored token counts in thousands while the billing writer priced them as raw tokens. One later row used a stale region, so the price was close enough to look plausible.
That is the kind of task where an agent can sound competent while still being wrong. It can say “I found the issue” and still miss one corrupted row. It can fix the obvious unit mistakes and overcorrect clean rows from the same batch. It can write a tidy incident report and quietly use the wrong regional multiplier.
That is why I wanted an eval, not a demo. By eval, I mean a repeatable test of
what an agent did and whether a task-specific grader can prove the result was
right. I also packaged the complete example as a forkable repo:
silentvoice/harbor-token-ledger-eval.
My goal was not to benchmark a model. My goal was to understand the mechanics of a real agent eval:
| Question I wanted answered | What the eval needed |
|---|---|
| What exactly does the agent see? | A sealed filesystem: CSVs and notes are present, hidden tests are not, and internet is off. |
| What exactly must the agent create? | A SQL repair script and a JSON incident report. |
| How do I know it is right? | A hidden verifier, or grading script, that runs after the agent. |
| How do I debug a miss? | Artifacts, reward details, and the agent trajectory. |
| How do I know the task itself is fair? | An oracle run: Harbor’s reference agent runs my known-good solution. |
Harbor’s pieces make more sense when they arrive in that order. I need the files the agent can see, then an instruction, then a verifier, then agents, then traces.
Fork the GitHub repo if you want to run or modify the eval. I mirrored the task
files here for easier reading; a good local starting point is
task.toml.
The repo quick start is intentionally short:
git clone https://github.com/silentvoice/harbor-token-ledger-eval.git
cd harbor-token-ledger-eval
./scripts/run_oracle.sh
./scripts/run_weak_agent.shThe oracle should score 1.0000. The weak agent should score 0.7063, and
Harbor will print the job directory where you can open verifier/reward.json
and verifier/details.json.
The Problem
The agent gets a miniature billing incident. The files are small enough to read, but not so tiny that string matching would prove anything.
The problem statement is:
Given provider usage events, a current billing ledger, pricing tables, and ingestion notes, create a SQL repair script and an incident report. The repair must use provider events as truth, fix only the wrong rows, reprice with the correct model and region, and leave clean rows alone.
That is the whole task in human language. The agent is not being asked to chat about the ledger or recommend next steps. It has to leave behind two files that another program can grade:
| Required file | What it must contain |
|---|---|
/app/fix.sql | A SQLite script that creates a corrected ledger table. |
/app/incident_report.json | A structured report with affected event IDs, root cause, total dollar delta, validation checks, and risk level. |
| File | What it means |
|---|---|
provider_events.csv | Source-of-truth usage events from the metering provider. |
billing_ledger.csv | Current warehouse ledger. Some rows are wrong. |
rate_card.csv | Model prices per million input and output tokens. |
region_multipliers.csv | Multipliers for us, eu, and apac. |
ingestion_notes.md | Deployment clues from the ingestion pipeline. |
Here are the rows that make the task interesting:
| Event | Provider truth | Ledger value | What should happen |
|---|---|---|---|
E-2003 | 2,200,000 / 480,000 tokens | 2,200 / 480 units | Correct token-unit drift. |
E-2004 | 560,000 / 90,000 tokens | 560 / 90 units | Correct token-unit drift. |
E-2007 | 3,150,000 / 720,000 tokens | 3,150 / 720 units | Correct token-unit drift. |
E-2010 | 780,000 / 210,000 tokens | 780 / 210 units | Correct token-unit drift. |
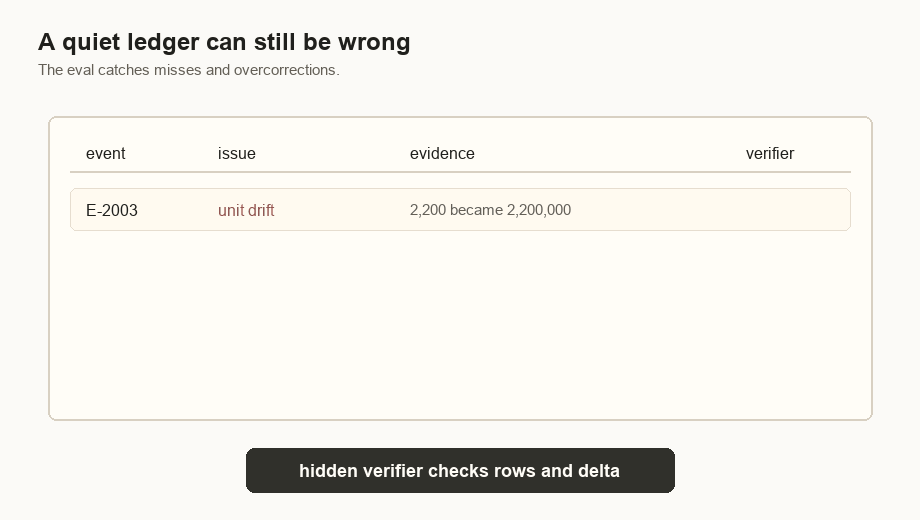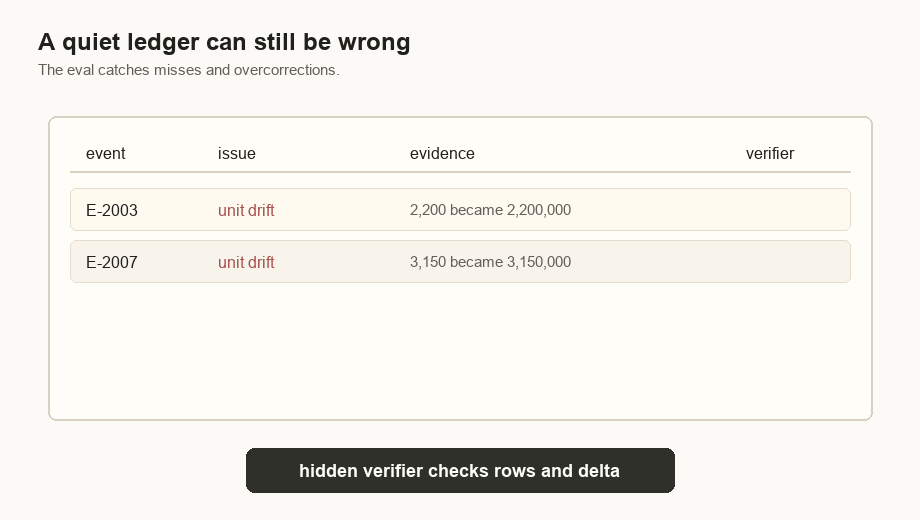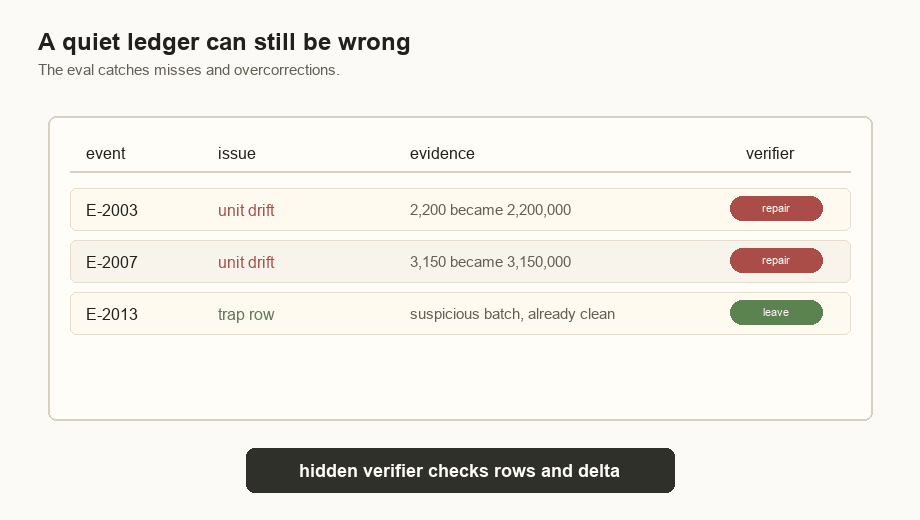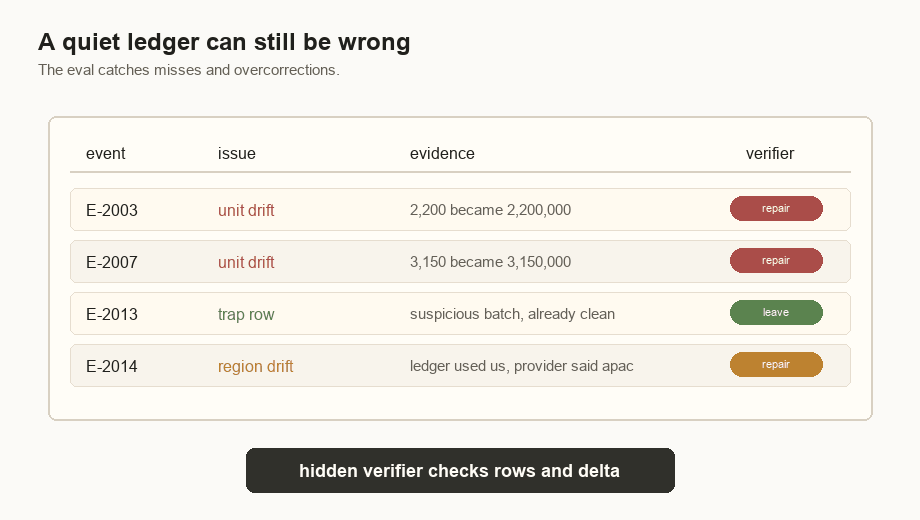
E-2013 | 1,230,000 / 330,000 tokens | 1,230,000 / 330,000 units | Leave unchanged. |
E-2014 | Provider region is apac | Ledger region is us | Reprice with provider region. |
That E-2013 row matters. A weak agent might read the deployment note and
decide every row in batch_2026_05_18 needs to be multiplied by 1,000. That
would be plausible and wrong.
Before writing any Harbor files, I wrote the human review checklist:
- Does the answer include every provider event exactly once?
- Does it use raw provider token counts?
- Does it price each row with the right model rate and provider region?
- Does it identify only the rows that actually changed?
- Does the incident report explain both causes?
- Did the agent avoid editing the input files?
That checklist becomes the verifier later. This is the first useful mental move: do not start with “how should Harbor score this?” Start with “what would I check if I reviewed the output by hand?”
The Agent And Its Tools
In Harbor, an agent is the runner that receives the instruction, acts inside the task environment, and leaves artifacts behind. The agent might wrap a model, like Claude Code, or it might be a deterministic Python class. The verifier does not care which one it is. It only cares about the files the agent produced.
For this walkthrough, I used deterministic agents so the example is reproducible without my model credentials:
| Agent | What it represents | Tool/action it uses |
|---|---|---|
nop | Empty baseline. | Does not write the required files. |
token-ledger-agent-v0 | Weak baseline that trusts the bad ledger. | Runs a command in the container and writes a flawed fix.sql plus JSON report. |
token-ledger-agent | Passing baseline. | Runs a command in the container and writes the repaired SQL plus incident report. |
oracle | Task sanity check. | Runs the reference solution from solution/solve.sh. |
The custom agents use Harbor’s environment execution hook. In code, that means
they call environment.exec(...) to run a command inside the task container.
That command writes /app/fix.sql and /app/incident_report.json.
The agent is allowed to use:
| Allowed | Why |
|---|---|
/app/provider_events.csv, /app/billing_ledger.csv, /app/rate_card.csv, /app/region_multipliers.csv, /app/ingestion_notes.md | These are the visible task files copied into the container. |
| Shell commands inside the container | The agent can inspect files, compute values, and write outputs. |
/app/fix.sql and /app/incident_report.json | These are the artifact paths Harbor collects after the run. |
The agent is not allowed to use:
| Not visible | Why it matters |
|---|---|
tests/score.py | This is the hidden verifier. If the agent can read it, the eval becomes a worksheet. |
solution/solve.sh | This is only for the oracle run. |
| The internet | allow_internet = false keeps the task about the provided evidence. |
| Edited input CSVs | The verifier gives safety credit only if source files stay unchanged. |
That tool boundary is the practical meaning of an eval environment. The agent gets enough power to solve the task, but not enough information to fake the grade.
The Harbor Task
A Harbor task is a folder with a contract. The docs describe the task shape as
task.toml, instruction.md, environment/, tests/, and optionally
solution/. The important detail is visibility: the agent sees the instruction
and environment, but it does not see the hidden tests or reference solution.
My task folder is named token-ledger-repair. The local static copy in this
site is under token-ledger-example only because it also includes article
extras such as sample rewards and agent files.
token-ledger-repair/
├── task.toml
├── instruction.md
├── environment/
│ ├── Dockerfile
│ ├── provider_events.csv
│ ├── billing_ledger.csv
│ ├── rate_card.csv
│ ├── region_multipliers.csv
│ └── ingestion_notes.md
├── tests/
│ ├── test.sh
│ └── score.py
└── solution/
└── solve.sh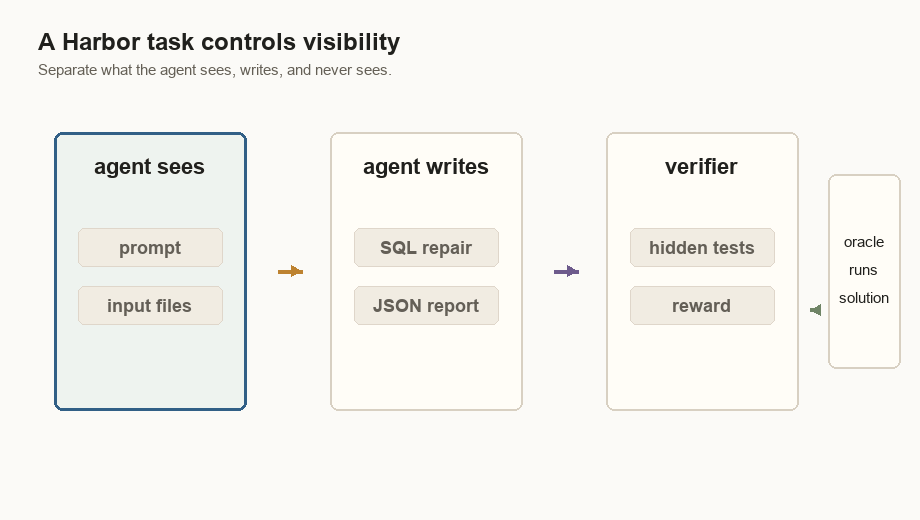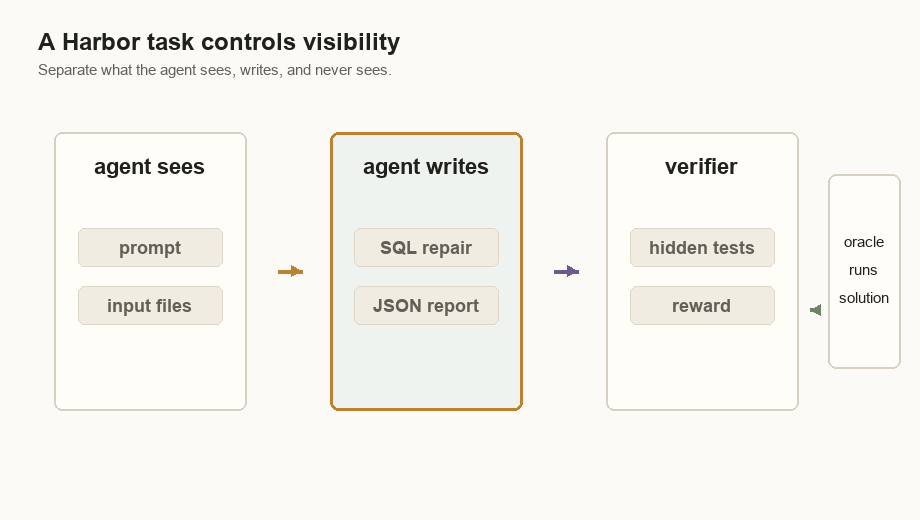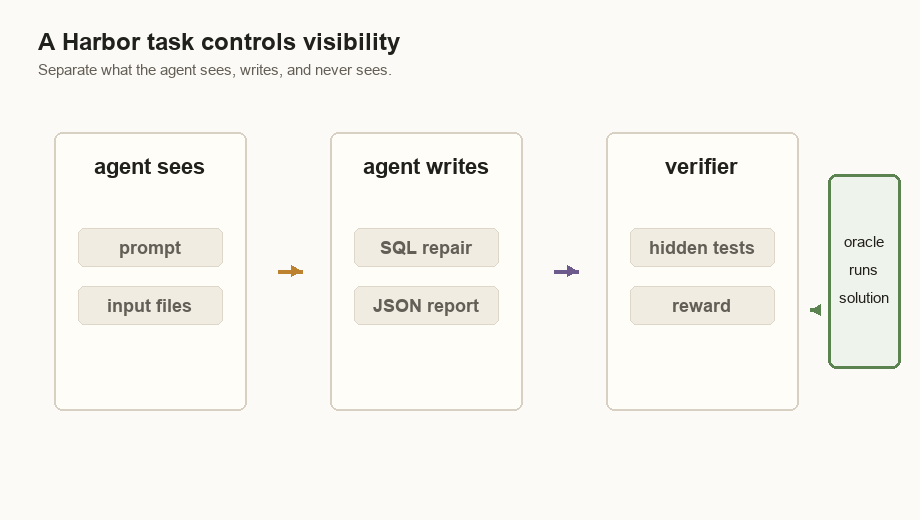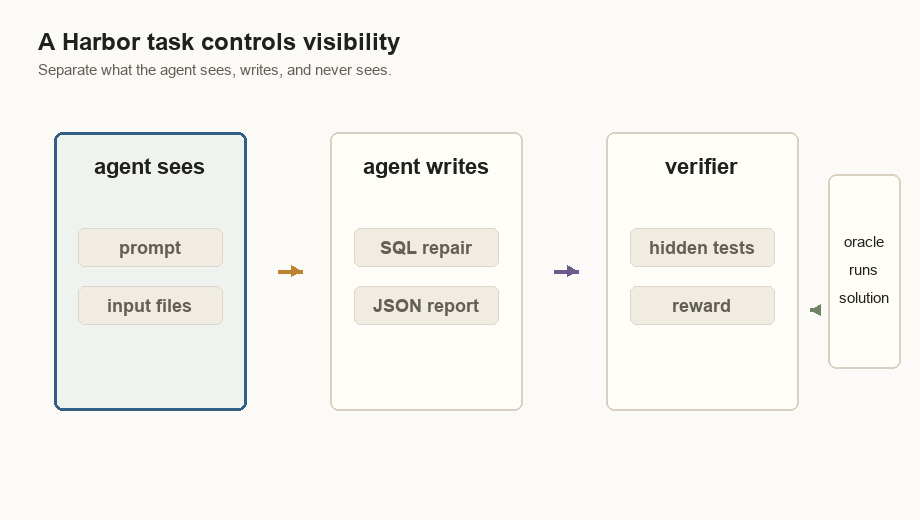
The Dockerfile is deliberately plain:
FROM python:3.13-slim-bookworm
WORKDIR /app
COPY provider_events.csv /app/provider_events.csv
COPY billing_ledger.csv /app/billing_ledger.csv
COPY rate_card.csv /app/rate_card.csv
COPY region_multipliers.csv /app/region_multipliers.csv
COPY ingestion_notes.md /app/ingestion_notes.mdThat file answers “what does the agent see?” It sees /app/*.csv and
/app/ingestion_notes.md. It does not see tests/score.py. It does not see
solution/solve.sh. There is no CMD; Harbor starts and controls the
container while it injects the agent and verifier steps.
The task.toml says what Harbor should collect and how constrained the run
should be:
schema_version = "1.1"
artifacts = ["/app/fix.sql", "/app/incident_report.json"]
[task]
name = "local/token-ledger-repair"
description = "Evaluate whether an agent can diagnose and repair silent unit and region drift in a usage billing ledger."
keywords = ["billing", "data-quality", "sqlite", "incident", "ledger"]
[agent]
timeout_sec = 180.0
[verifier]
timeout_sec = 120.0
[environment]
cpus = 1
memory_mb = 1024
allow_internet = falseThe artifact list is worth calling out. Harbor copies those files out of the container after each run, so I can inspect what the agent wrote instead of only seeing a score.
The Instruction Is The Output Contract
The instruction is not a vibe. It is the agent-facing contract.
I gave the agent two outputs:
| Output | Purpose |
|---|---|
/app/fix.sql | SQLite script that creates a corrected ledger table. |
/app/incident_report.json | Structured explanation of what changed and why. |
The SQL output must create this table:
CREATE TABLE corrected_ledger (
event_id TEXT,
input_tokens INTEGER,
output_tokens INTEGER,
amount_usd REAL,
correction_reason TEXT
);The pricing formula is part of the instruction:
((input_tokens / 1_000_000) * input_price_per_million
+ (output_tokens / 1_000_000) * output_price_per_million)
* region_multiplierAnd the report has a small schema. In the instruction, the values are described by type and meaning, not by the hidden expected answer:
| Field | Type | Meaning |
|---|---|---|
affected_events | array of strings | Event IDs whose corrected row differs from the ledger. |
root_cause | string | Short explanation of what went wrong. |
total_delta_usd | number | Total correction delta, rounded to 6 decimal places. |
checks | array of strings | Validation checks the agent used. |
risk_level | string | One of medium or high for this incident. |
The actual instruction does not include the expected answer, of course. It only
defines the shape:
instruction.md.
It does make the grading language visible: unit drift, stale region, and
unchanged rows need to be named clearly in correction_reason, and the report’s
root_cause needs to mention both bug classes. That is not giving away the
answer. It is telling the agent what kind of explanation counts.
This is where a lot of agent evals quietly fail. If I cannot state the output contract, I cannot grade the output without relying on taste. Harbor does not remove that work. It makes the work visible.
The Verifier Is The Eval
The verifier is the part I trust. In this task, Harbor runs
tests/test.sh
after the agent exits:
#!/bin/sh
set -eu
if ! python3 /tests/score.py; then
mkdir -p /logs/verifier
cat > /logs/verifier/reward.json <<'JSON'
{
"coverage": 0,
"diagnosis": 0,
"pricing": 0,
"report": 0,
"reward": 0,
"safety": 0,
"schema": 0,
"units": 0
}
JSON
printf '0' > /logs/verifier/reward.txt
fiThat script executes
score.py. The
verifier loads the CSVs into SQLite, runs the agent’s /app/fix.sql, checks the
resulting corrected_ledger, reads /app/incident_report.json, and writes
/logs/verifier/reward.json.
The reward is not a single magic score. I split it into named dimensions:

The weights are intentionally simple:
reward = round(
0.15 * schema
+ 0.15 * coverage
+ 0.20 * units
+ 0.20 * pricing
+ 0.10 * diagnosis
+ 0.15 * report
+ 0.05 * safety,
4,
)Here is what each dimension means:
| Dimension | What it catches |
|---|---|
schema | Did the SQL create the expected table and columns? |
coverage | Did it include every provider event exactly once? |
units | Did it recover raw token counts instead of trusting drifted ledger units? |
pricing | Did it apply model rates and provider-region multipliers? |
diagnosis | Did each row’s correction_reason match what happened? |
report | Did the JSON report name the affected rows, delta, cause, checks, and risk? |
safety | Did the input CSVs remain unchanged? |
The hidden tests also write details.json, which is the file I read when a run
fails. The score tells me something is wrong. The details tell me where to look.
The Oracle Tests The Task
Before I ran any real agent, I ran Harbor’s oracle. The oracle is Harbor’s
built-in reference agent. It runs solution/solve.sh and then sends that output
through the same verifier.
The command looked like this:
harbor run \
-p /path/to/token-ledger-repair \
-a oracle \
--jobs-dir .astro/harbor-runs/token-ledger-oracle-v2 \
--yes \
--n-concurrent 1 \
--force-build \
--artifact /app/fix.sql \
--artifact /app/incident_report.jsonThe oracle got 1.0:
adhoc - oracle
coverage 1.000
diagnosis 1.000
pricing 1.000
report 1.000
reward 1.000
safety 1.000
schema 1.000
units 1.000That mattered because my first oracle run did not pass. I had put the wrong
expected total_delta_usd in the reference incident report. The verifier caught
my mistake. That is exactly why I like running the oracle first: if the
reference solution cannot pass, I do not have an agent problem yet. I have a
task problem.
Agents Are Swappable
Once the task and verifier agreed, I ran four agents:
| Agent | What it does | Reward |
|---|---|---|
nop | Does nothing. | 0.0000 |
token-ledger-agent-v0 | Trusts the billing ledger as-is. | 0.7063 |
token-ledger-agent | Uses provider events as truth and repairs the rows. | 1.0000 |
oracle | Runs the reference solution. | 1.0000 |

The no-op baseline is not silly. It confirms the verifier gives no credit when the required artifacts are missing.
token-ledger-agent-v0 is more interesting. It writes a valid table and covers
every row, but it copies the drifted ledger values:
{
"coverage": 1.0,
"diagnosis": 0.6875,
"pricing": 0.6875,
"report": 0.0,
"reward": 0.7063,
"safety": 1.0,
"schema": 1.0,
"units": 0.75
}The verifier details explain the miss:
{
"event_id": "E-2007",
"field": "tokens",
"expected": [3150000, 720000],
"got": [3150, 720]
}And another miss:
{
"event_id": "E-2014",
"field": "amount_usd",
"expected": 2.768125,
"got": 2.6875
}That is the moment the eval becomes useful. I do not have to argue whether the agent “understood” the incident. The output is wrong in a way I can point to.
The custom agents are tiny Harbor agents. The improved one is here:
token_ledger_agent.py.
The intentionally weak one is here:
token_ledger_agent_v0.py.
For a real model-backed run, Harbor also exposes installed agents. Installed agents ship with Harbor; custom agents are local Python files like the two above. The command shape for Claude Code is a flag change:
harbor run \
-p /path/to/token-ledger-repair \
-a claude-code \
-m anthropic/claude-opus-4-7I also ran the installed Claude Code agent, and it turned into a useful setup note. My sealed task had
allow_internet = false, while Harbor’s installed Claude Code agent wanted to
install CLI dependencies inside the container. An online copy got past that
step, then the agent stderr had the useful clue:
Not logged inThat is not a verifier failure; it is an agent-runtime setup issue. The agent
never reached the point where the hidden tests could judge fix.sql or
incident_report.json. For this article I kept the evidence on deterministic
agents so every score shown here is reproducible without my account.
Artifacts Make The Score Inspectable
Harbor stores the run output in a job directory. For the passing agent, the files looked like this:
token-ledger-repair__qrP7nw2/
├── agent/
│ ├── token-ledger-agent-command.txt
│ ├── token-ledger-agent-stdout.txt
│ ├── token-ledger-agent-stderr.txt
│ └── trajectory.json
├── artifacts/
│ ├── fix.sql
│ ├── incident_report.json
│ └── manifest.json
├── verifier/
│ ├── details.json
│ ├── reward.json
│ └── test-stdout.txt
└── result.jsonThe artifacts/ directory is where I look first. Did the agent write the files
I asked for? Are they shaped the way the instruction said?
The passing fix.sql joins provider events, ledger rows, rates, and
multipliers:
CREATE TABLE corrected_ledger AS
SELECT
p.event_id AS event_id,
CAST(p.input_tokens AS INTEGER) AS input_tokens,
CAST(p.output_tokens AS INTEGER) AS output_tokens,
ROUND(
(
(CAST(p.input_tokens AS REAL) / 1000000.0) * CAST(r.input_price_per_million AS REAL)
+ (CAST(p.output_tokens AS REAL) / 1000000.0) * CAST(r.output_price_per_million AS REAL)
) * CAST(m.multiplier AS REAL),
6
) AS amount_usd,
CASE
WHEN CAST(l.input_units AS INTEGER) != CAST(p.input_tokens AS INTEGER)
OR CAST(l.output_units AS INTEGER) != CAST(p.output_tokens AS INTEGER)
THEN 'corrected token unit drift from thousands to raw tokens'
WHEN l.region != p.region
THEN 'corrected stale ledger region using provider region multiplier'
ELSE 'unchanged: ledger units already matched provider raw tokens'
END AS correction_reason
FROM provider_events p
JOIN billing_ledger l ON l.event_id = p.event_id
JOIN rate_card r ON r.model = p.model
JOIN region_multipliers m ON m.region = p.region;The key choice is m.region = p.region. That uses the provider region instead
of trusting the ledger region, which is how E-2014 gets fixed.
The incident_report.json names the affected events and expected delta. The
passing report was complete:
{
"affected_events": ["E-2003", "E-2004", "E-2007", "E-2010", "E-2014"],
"root_cause": "The 2026-05-18 ingestion deployment wrote token counts in thousands into a billing writer that still expected raw token units, and one 2026-05-19 enrichment retry reused a stale ledger region.",
"total_delta_usd": 20.279625,
"checks": [
"Compared billing_ledger units against provider_events raw token counts.",
"Repriced every row with rate_card prices per million tokens and region multipliers.",
"Checked that affected events align with ingestion_notes.md while leaving clean rows in the same batch unchanged."
],
"risk_level": "high"
}This is also why I prefer structured artifacts over prose-only answers. A verifier can run SQL. It can parse JSON. It can compare numbers. It cannot reliably grade a confident paragraph unless I turn that paragraph into a contract first.
The Trajectory Is The Debug Trail
Harbor can store agent trajectories in the Agent Trajectory Interchange Format (ATIF), a portable JSON shape for the steps in an agent run. I do not need the full trace for every successful run, but I want it when a score surprises me.
The simplified trace from my passing demo has three steps:
{
"schema_version": "ATIF-v1.4",
"agent": {
"name": "token-ledger-agent",
"version": "0.1.0",
"model_name": "deterministic"
},
"steps": [
{
"source": "user",
"message": "# Token Ledger Repair ..."
},
{
"source": "agent",
"message": "Compare provider_events against billing_ledger..."
},
{
"source": "environment",
"observation": {
"results": [
{
"source_call_id": "write_fix",
"content": "return_code=0"
}
]
}
}
]
}The trace is not the grade. The verifier is the grade. The trace is how I debug the grade.
If an agent failed pricing, I would inspect the trace for the moment it chose
ledger region over provider region. If it failed report, I would inspect
whether it ever computed the total delta or only wrote a narrative summary. If
it failed safety, I would inspect whether it edited the input CSVs instead of
creating a separate corrected table.
How I Would Build My Own Harbor Eval
The reusable pattern is smaller than it looks.

Here is the checklist I would use again:
-
Pick a failure that has evidence.
“The agent should help with billing” is too broad. “The agent should repair rows where provider usage and ledger usage disagree” is gradeable.
-
Freeze the world.
Put every file the agent may use in
environment/. Use the Dockerfile to copy only those files into/app. -
Define the output paths.
Make the agent write files with predictable names. If the answer is unstructured prose, first ask whether you can make the important parts JSON, SQL, CSV, or another checkable format.
-
Write the verifier as if it were a human review checklist.
Start with dimensions before weights. In this task I cared about schema, coverage, units, pricing, diagnosis, report, and safety.
-
Run the oracle.
If
solution/solve.shdoes not get full credit, fix the task or verifier before blaming an agent. -
Run weak agents on purpose.
A no-op agent should score zero. A weak-but-valid agent should get partial credit. If every wrong answer gets zero, the verifier may be too brittle. If every plausible answer passes, it may be too soft.
-
Read the artifacts.
The most useful Harbor output is often not
reward = 0.7063. It is the mismatch that saysE-2007expected3,150,000tokens and got3,150.
Tips
Use provider truth when you have it. In this task, the whole eval depends on knowing which file is authoritative. If every file is equally trustworthy, the verifier turns into a debate.
Add at least one trap row. The clean rows inside the suspicious batch made the task better because they punished lazy rules like “multiply every May 18 row by 1,000.”
Do not hide all feedback in the final reward. Named dimensions make the score
actionable. token-ledger-agent-v0’s 0.7063 mattered less than seeing units = 0.75
and pricing = 0.6875.
Keep the oracle boring. The reference solution is not where I want cleverness. It is there to prove the task can be solved and the verifier can recognize the solution.
Be honest about operational setup. Installed agents such as Claude Code may need package installation and credentials inside the task container. That is separate from whether the verifier is good. For a sealed eval, pre-bake the agent dependencies or use a custom agent wrapper that does not need network setup during the run.
Prefer artifacts over screenshots of success. A passing run should leave behind
the files that explain why it passed: fix.sql, incident_report.json,
reward.json, details.json, and the trajectory.
I stopped thinking of Harbor as “an eval framework” and started thinking of it as a disciplined way to answer one question: what did the agent do, and how do I know it was right?