LLM inference, from request to token
May 31, 2026Inference is the part of an LLM system that runs after training.
A user sends text. The server turns that text into token ids, runs the model, chooses the next token id, appends it to the request, and repeats. The answer arrives as a stream because the server is producing one token after another.
That is the core loop.
The hard part is everything around the loop. A real inference server has to keep many requests alive at once. It has to batch work without making people wait too long. It has to store the model’s memory of earlier tokens. It has to reuse shared prompt prefixes when it can. It has to split work across GPUs when one GPU is not enough. It has to stream clean text back to the client.
I read
nano-vllm and
Mini-SGLang because they make
that machinery small enough to study. I use them as source material, but the
article is about the inference stack itself: the loop, the model, the cache, the
scheduler, the serving boundaries, and the tricks that keep the GPU busy.
Vocabulary First
The rest of the article uses a handful of terms. I want them on the table before the architecture gets busy.
| Term | Plain meaning |
|---|---|
| Token | A number the model reads or writes. A token can be a word, part of a word, a space plus a word, or punctuation. |
| Tokenizer | The code that turns text into token ids and token ids back into text. |
| Prompt | The input tokens the user sends to the model. |
| Completion | The output tokens the model generates. |
| Logits | One score for each possible next token. |
| Sampler | The code that turns logits into the next token id. It may use greedy, temperature, top-k, or top-p sampling. |
| Request | One user’s live generation job: prompt, output tokens, cache state, sampling settings, and finish state. |
| Batch | A group of requests run together on the GPU. |
| Prefill | The first pass over the known prompt tokens. |
| Decode | The repeated step that produces one new token per request. |
| KV cache | GPU memory holding key and value vectors for earlier tokens, so decode does not recompute them. |
| Scheduler | The code that decides which requests run next and how much cache they get. |
| Page or block | A fixed-size piece of KV cache memory. |
| Prefix cache | A cache that reuses prompt work when two requests start with the same tokens. |
| Tensor parallelism | Splitting model weights across multiple GPUs. |
| CUDA graph | A captured GPU execution pattern that can be replayed to reduce CPU launch overhead. |
One more term matters: attention.
Attention is a lookup step inside the transformer. The current token is trying to update its vector. To do that, it asks which earlier tokens are useful.
That lookup has three parts:
| Part | Plain meaning | What it does |
|---|---|---|
| Query | The current token’s question. | It asks what kind of past information would help now. |
| Key | A label on an earlier token. | It is compared with the query to produce a match score. |
| Value | The information stored for that earlier token. | It is read when the key matches well. |
The model compares the query with all the old keys. Good matches get higher scores. Those scores become weights. The model then mixes the matching values back into the current token’s vector.
The KV cache stores those old keys and values so the model does not rebuild them on every decode step.
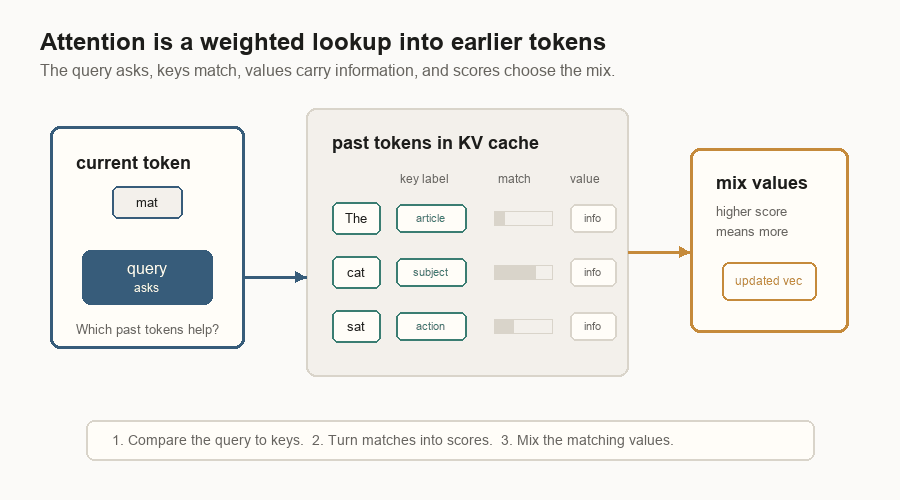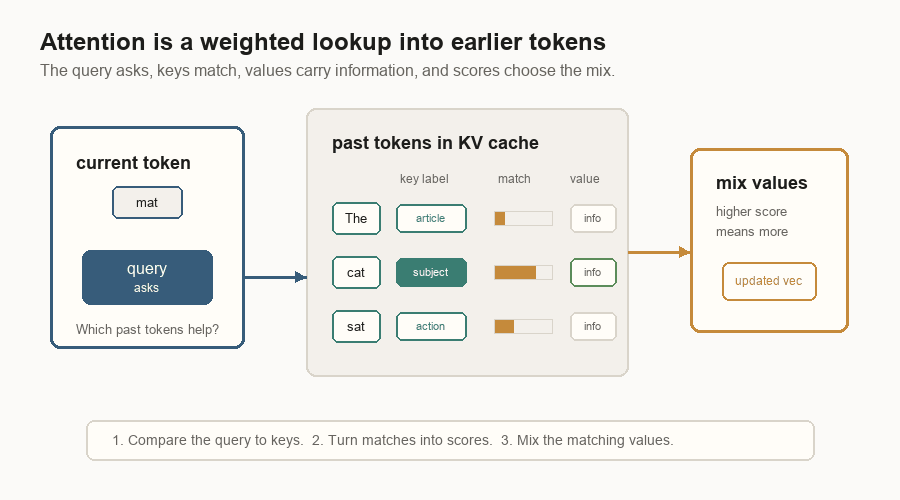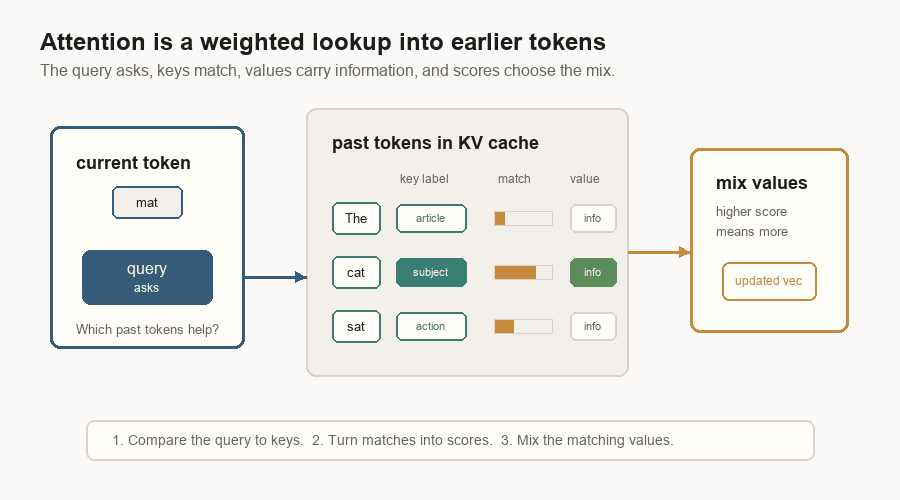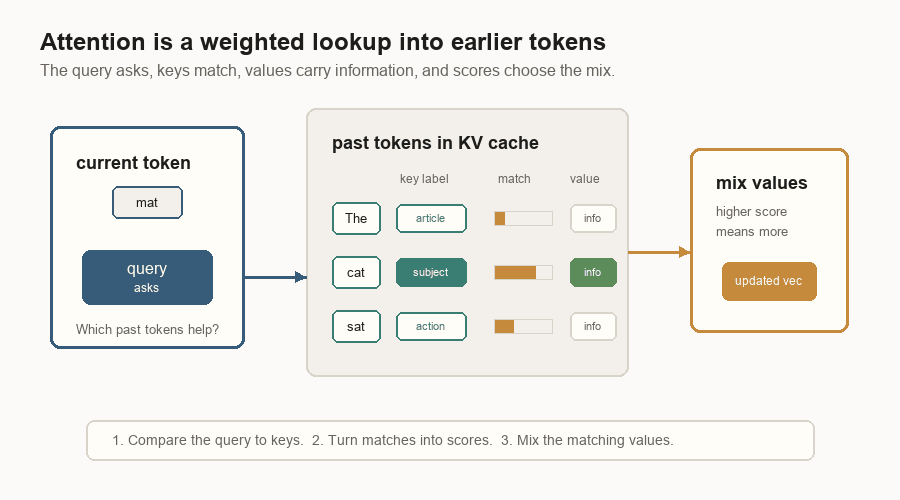
In the diagram, the current token is mat. Its query is not English text; it is
a learned vector. The earlier tokens have cached keys and values. The key for
cat matches best in this toy example, so the value from cat contributes the
most to the updated vector.
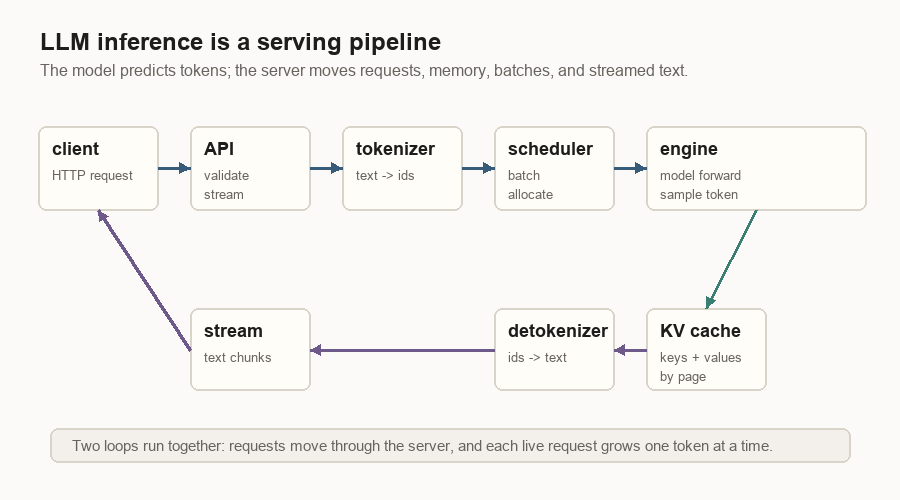
The Whole Request Path
Here is the server path without code names:
- The client sends a prompt and sampling settings.
- The API layer accepts the request.
- The tokenizer turns text into token ids.
- The scheduler decides when the request can run.
- The engine runs the model on the GPU.
- The sampler chooses the next token id.
- The scheduler appends that token and updates request state.
- The detokenizer turns token ids into text.
- The API layer streams the text chunk to the client.
- Steps 4 through 9 repeat until the request stops.
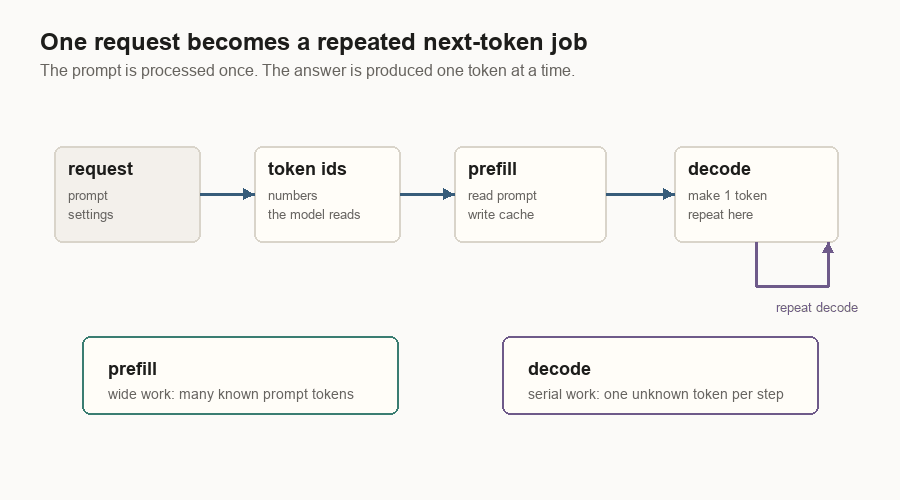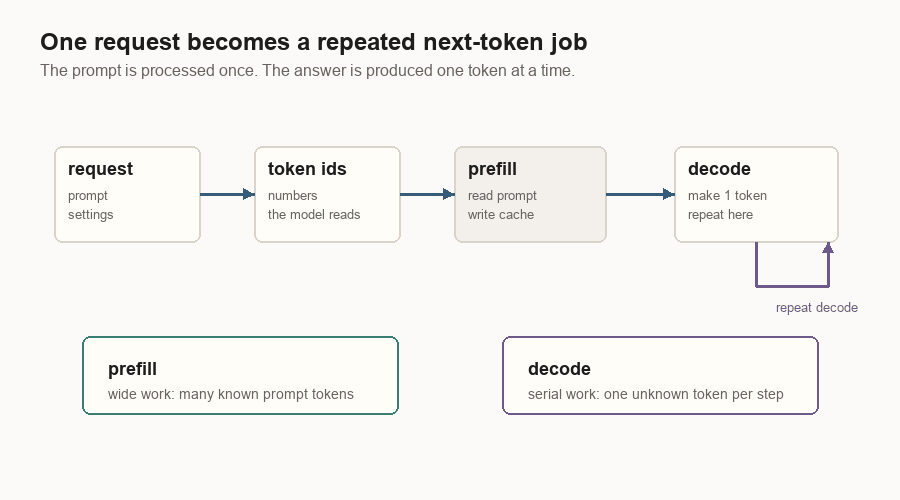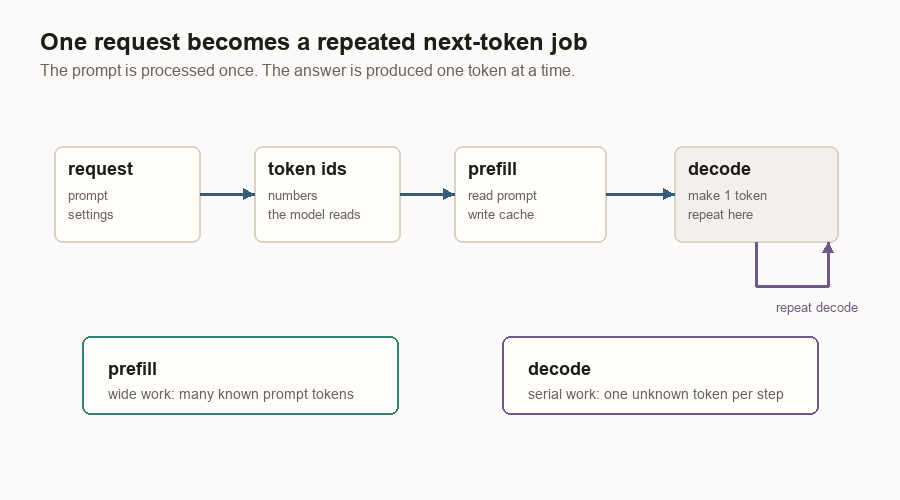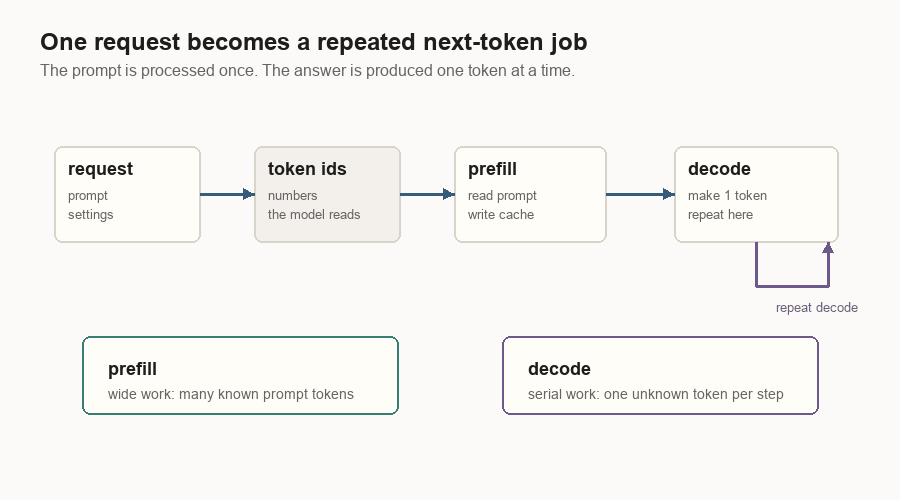
This path explains why an inference server is more than a model wrapper. The model forward pass is one piece. The server also owns request state, memory allocation, batching, cancellation, and streaming.
One Decode Step
Decode is the loop the user feels as streaming text.
At each decode step, every active request contributes its latest token. The model reads that token, the model weights, token positions, and the KV cache. It produces logits. The sampler picks one next token id. The server appends that token to the request and stores its new key and value vectors in the KV cache.
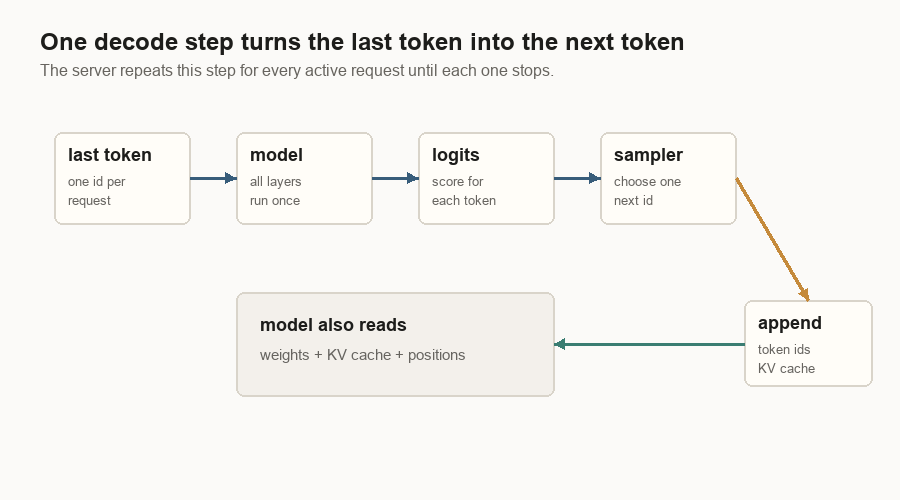
This is why LLM output is naturally sequential. Token 53 depends on token 52. Token 52 depends on token 51. The server can batch many users’ token-52 work together, but it cannot know one user’s token 53 before token 52 exists.
Prefill And Decode
Inference has two phases because the prompt and the answer behave differently.
Prefill handles the prompt. If the prompt has 700 tokens, all 700 are already known. The server can process a large slice of known tokens and fill the KV cache for them.
Decode handles the completion. Future output tokens are unknown. The server produces one token, appends it, and runs another decode step.
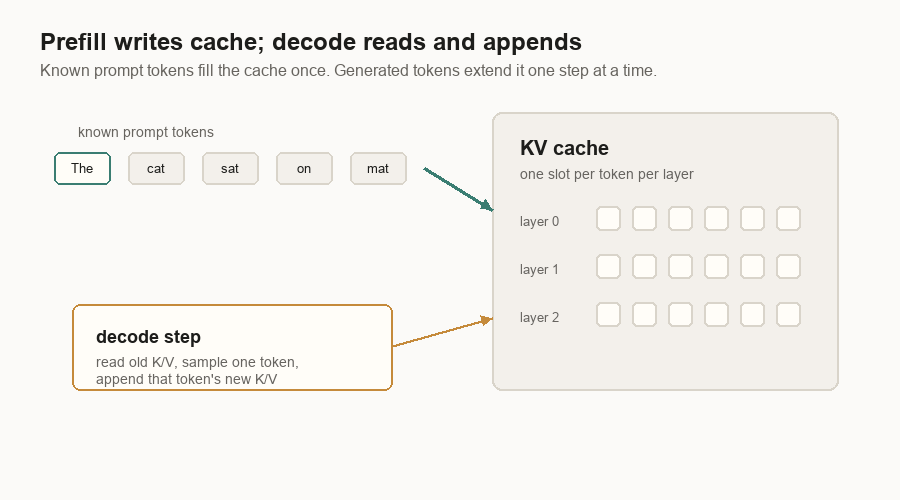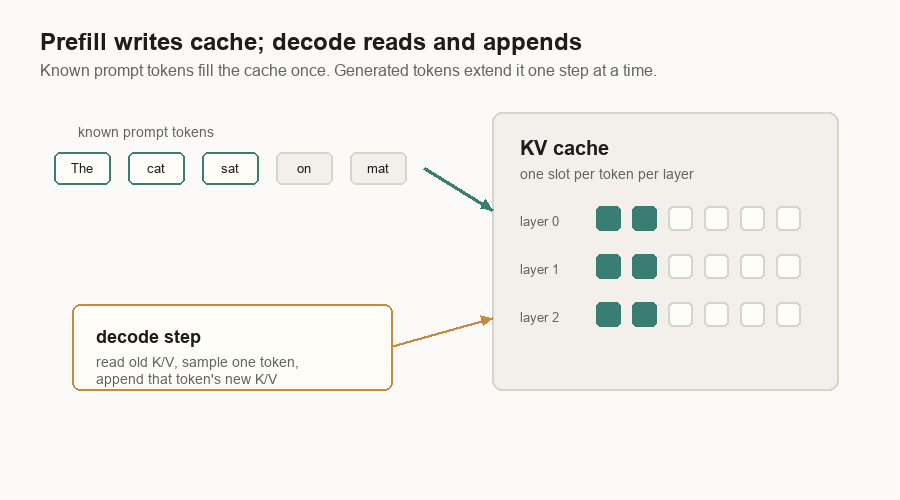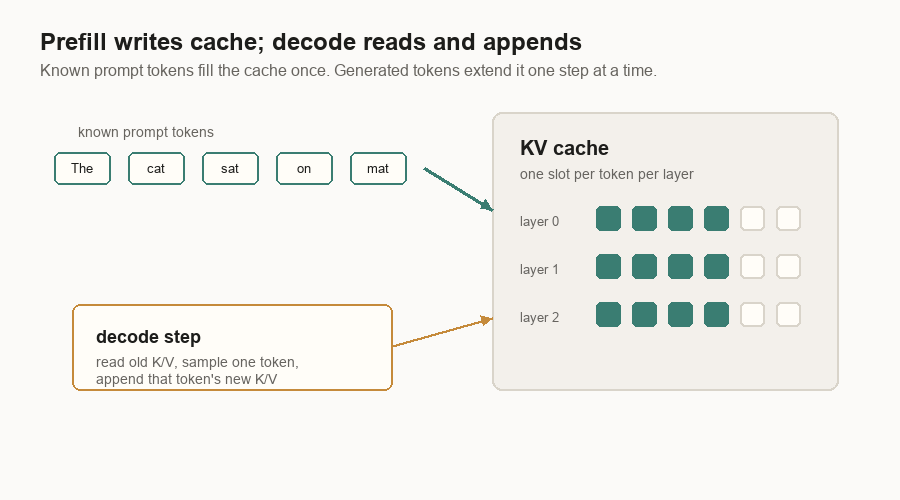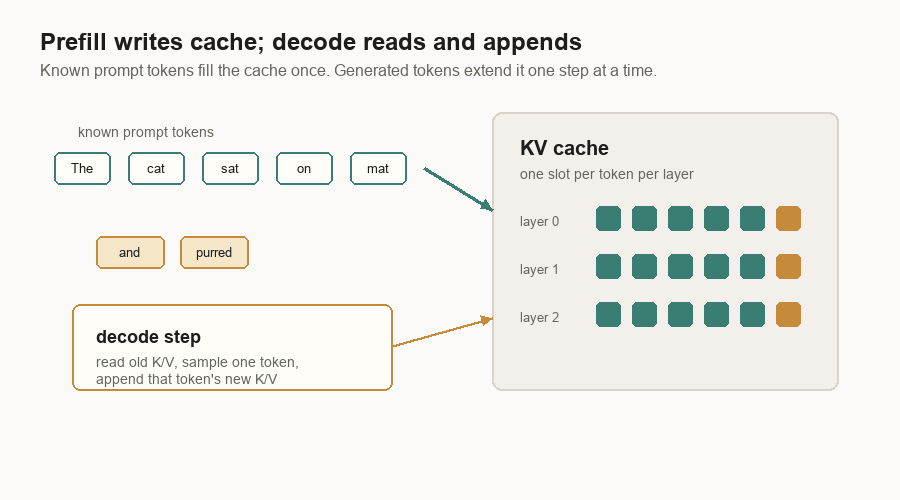
This split shows up everywhere in inference systems:
| Phase | Shape of work | Main pressure |
|---|---|---|
| Prefill | Many known prompt tokens at once. | Large token batches and cache allocation. |
| Decode | One new token per active request. | Repeated GPU launches, cache reads, and request scheduling. |
Many optimizations make sense only after this split is clear. Chunked prefill is about admitting long prompts without blowing up memory. CUDA graphs are mostly about making repeated decode steps cheaper. Prefix caching is about avoiding prefill work that another request already paid for.
What The Model Does
The model is a stack of transformer layers. A layer takes token vectors in and returns updated token vectors.
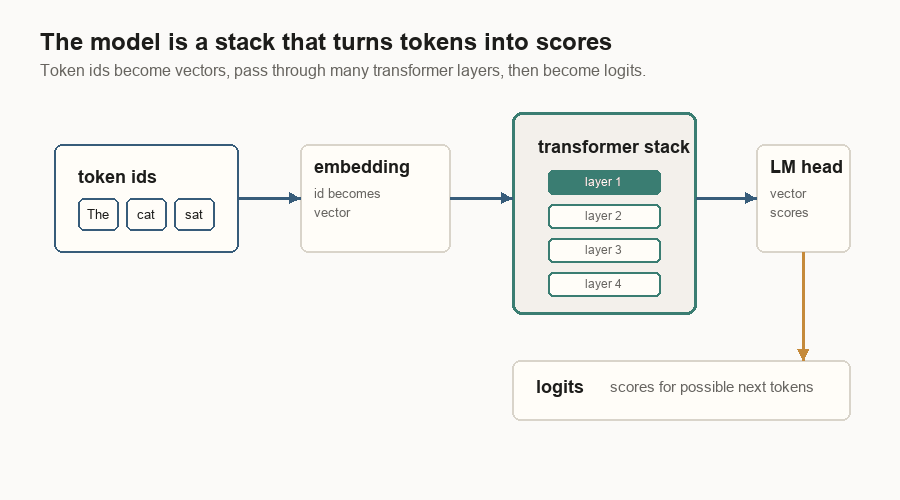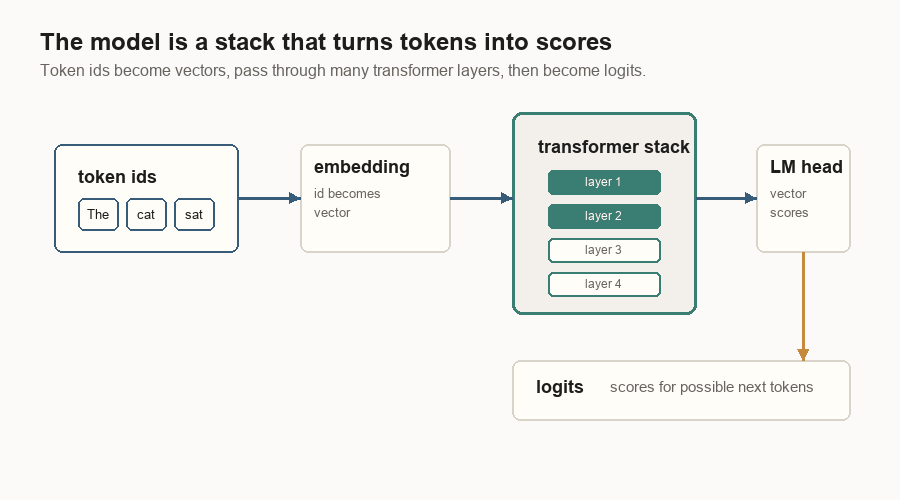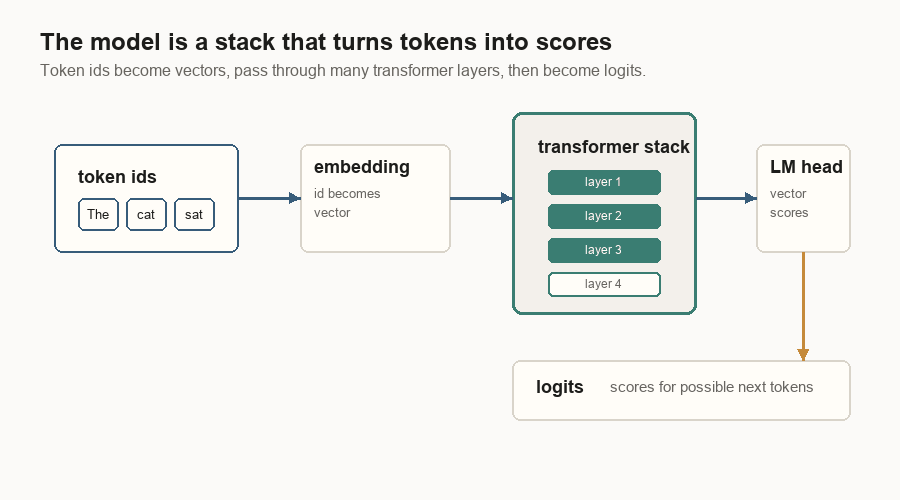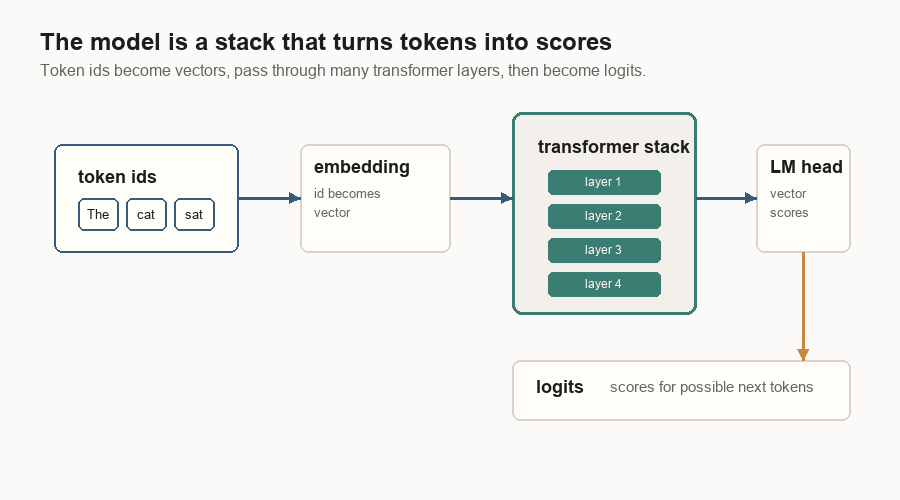
In a simplified transformer layer, the token vector goes through two main blocks.
First comes attention. The layer normalizes the vector, builds the query, key, and value views, adds position information to the query and key, then lets the current token read earlier values through attention.
Then comes the MLP, a small feed-forward network applied to the token vector. Both blocks have a residual connection: the old vector is copied around the block and added back to the block’s result. That copy path keeps information from being overwritten too easily as the vector moves through many layers.
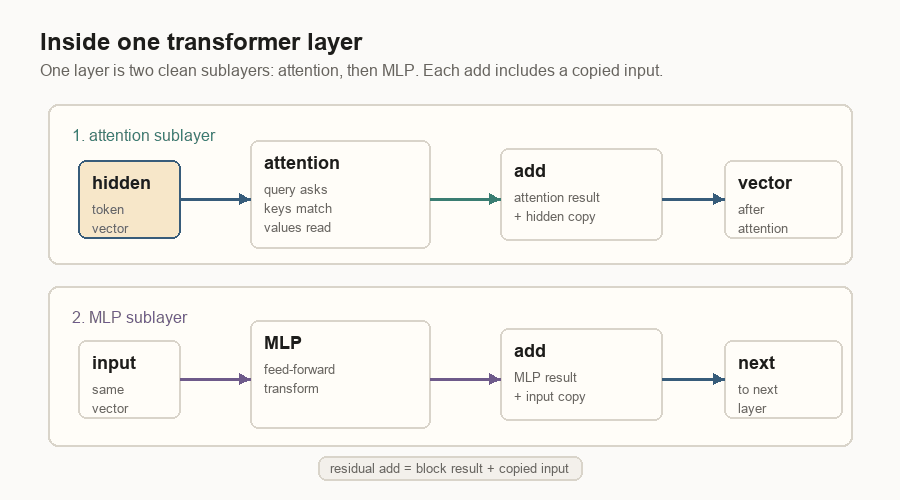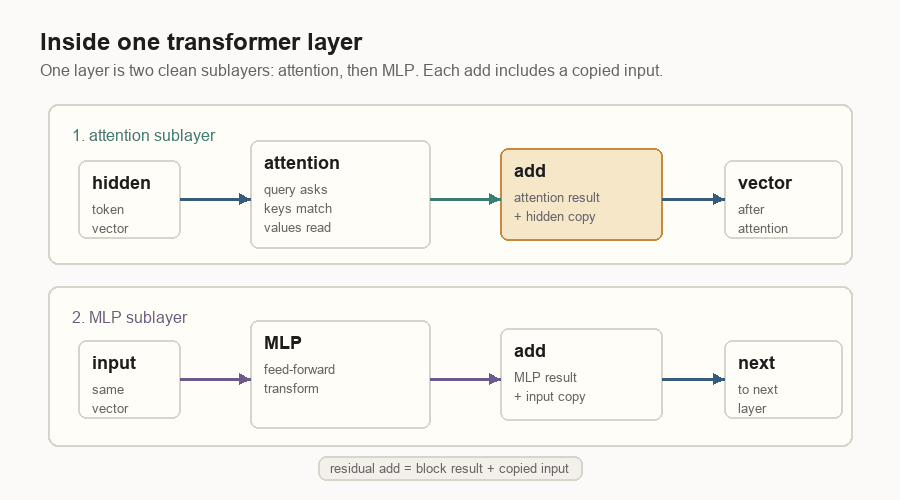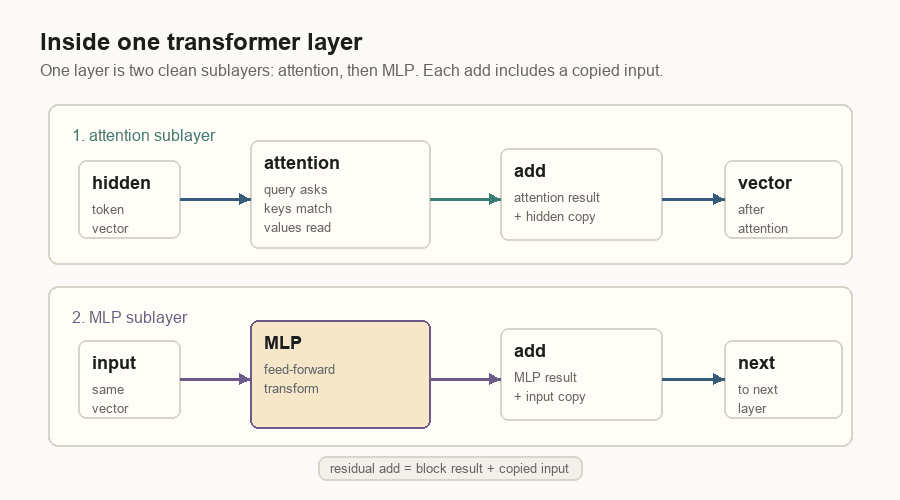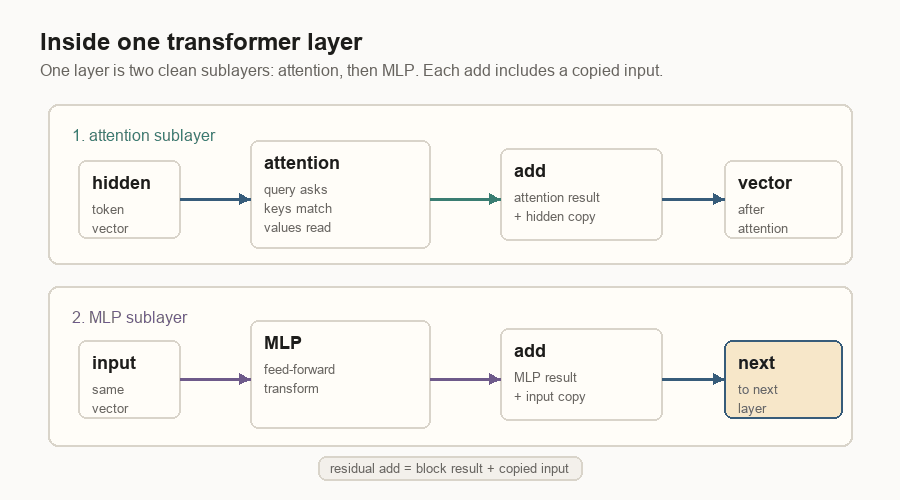
Every label in that diagram is doing a specific job:
| Label | Meaning |
|---|---|
| Hidden | The token vector entering this layer. |
| Attention | The part that uses query, key, and value to read earlier tokens. |
| Add | A residual add: block result plus the copied old vector. |
| MLP | A feed-forward network that transforms the token vector at this position. |
| Next | The updated vector passed to the next transformer layer. |
At the end of the stack, the language-model head turns hidden vectors into logits. A logit is just a score. The sampler converts those scores into one token id.
This is the model-side story. The serving-side story is how to feed this model efficiently for many live requests.
Sampling And Stopping
The model does not directly write text. It produces logits: one score for each token in the vocabulary. The sampler turns those scores into the next token id.
Sampling can be simple or controlled:
| Setting | Plain meaning |
|---|---|
| Greedy | Pick the highest-scoring token. |
| Temperature | Make the score distribution sharper or softer before sampling. |
| Top-k | Sample only from the k best-scoring tokens. |
| Top-p | Sample from the smallest group whose probabilities add up to p. |
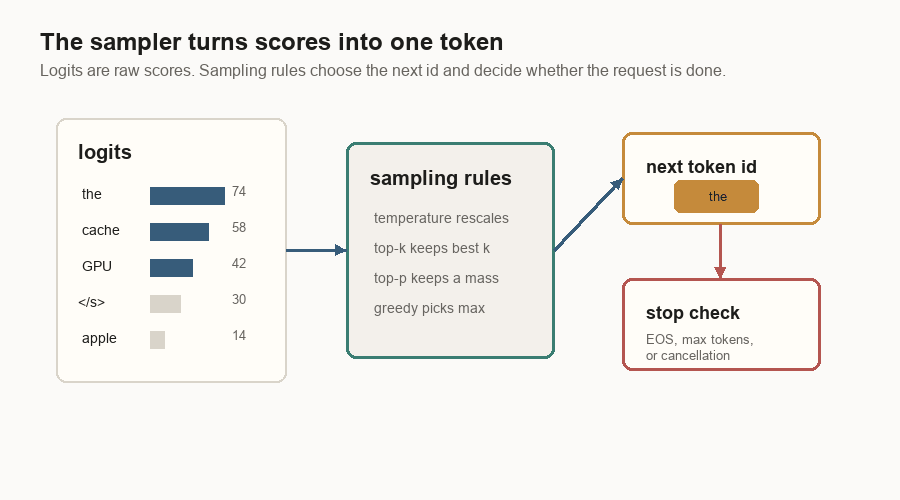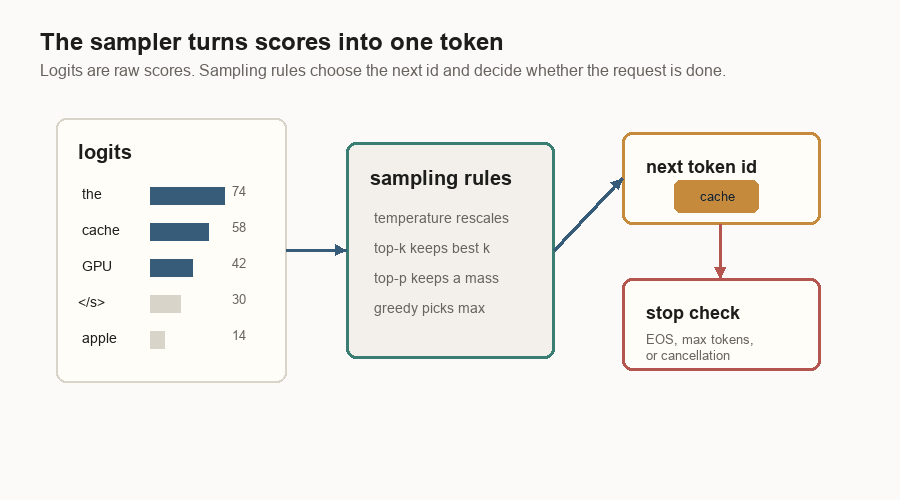
The request stops when it hits a stop condition: an end-of-sequence token, a maximum output length, a user-provided stop rule, or cancellation. Until then, the sampled token is appended and the scheduler brings the request back for another decode step.
The KV Cache
Without a KV cache, every decode step would recompute attention data for the whole prompt and all previous output tokens. That would be wasteful.
The cache stores key and value vectors for earlier tokens. Decode can then say: “I have one new query token. Read the old keys and values from cache. Store the new token’s keys and values for next time.”
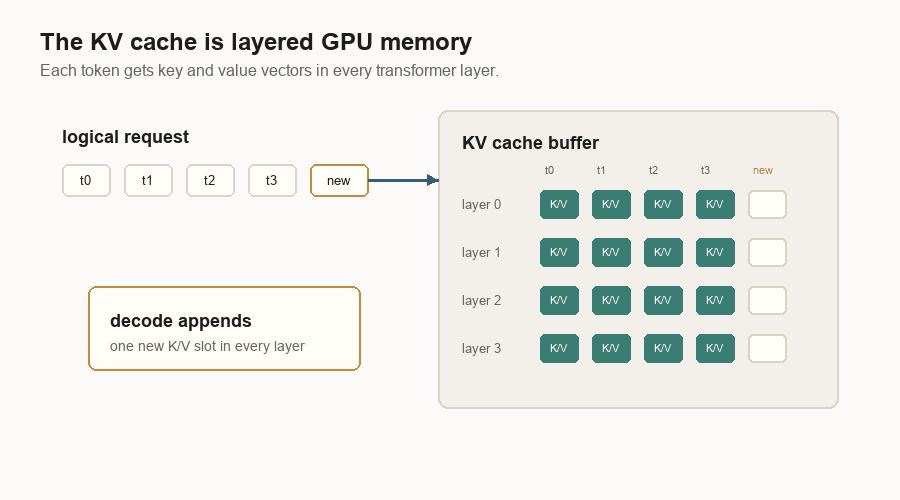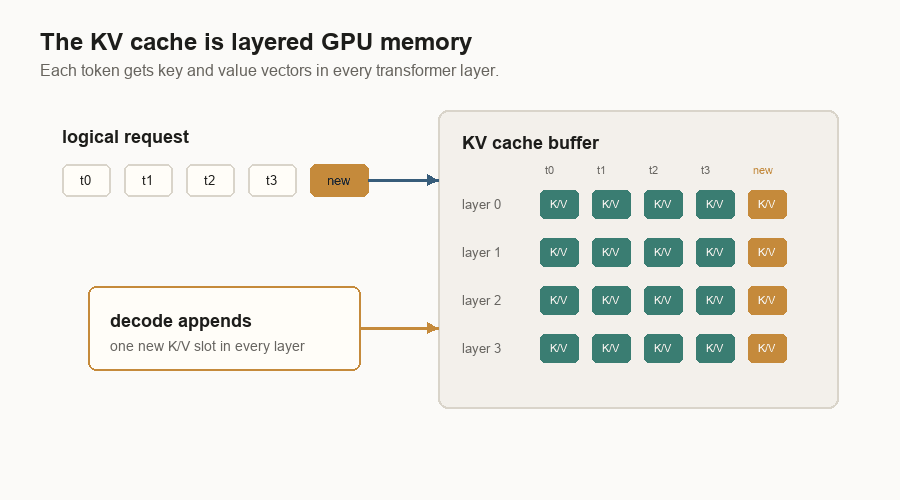
The cache grows with live tokens. If 100 requests are active, each with a long prompt and a long answer, the server is holding a lot of key/value vectors. That is why inference systems spend so much code on memory management.
The cache is also why prefill and decode are linked. Prefill writes the cache. Decode depends on it.
Scheduling And Batching
The scheduler decides what runs next.
It is balancing several goals:
| Goal | What can go wrong |
|---|---|
| High throughput | The GPU waits if batches are too small or CPU scheduling is slow. |
| Low latency | Users wait if the server delays a request too long to make a better batch. |
| Memory safety | The server fails if KV cache pages run out. |
| Fairness | A long prompt should not block all smaller requests forever. |
| Reuse | Shared prefixes should reuse cached work when possible. |
A simple scheduler keeps two groups of requests in mind: requests that still need prompt work, and requests that are ready to decode.
| Queue | Meaning |
|---|---|
| Waiting | Requests that still need prefill work. |
| Running | Requests that have finished prefill and can decode. |
The scheduler tries prefill first. It pulls requests from the waiting queue until it hits a request limit or a token budget. If no prefill batch can run, it schedules decode. Decode gives one token step to each running request that fits.
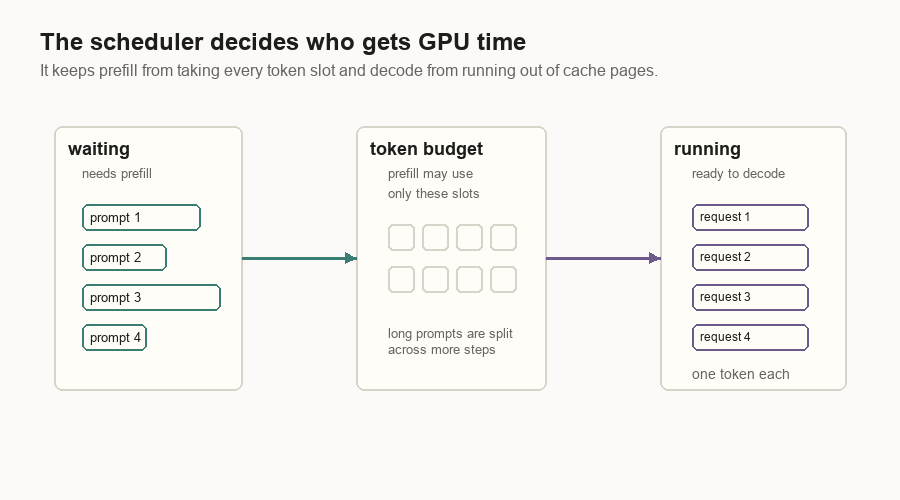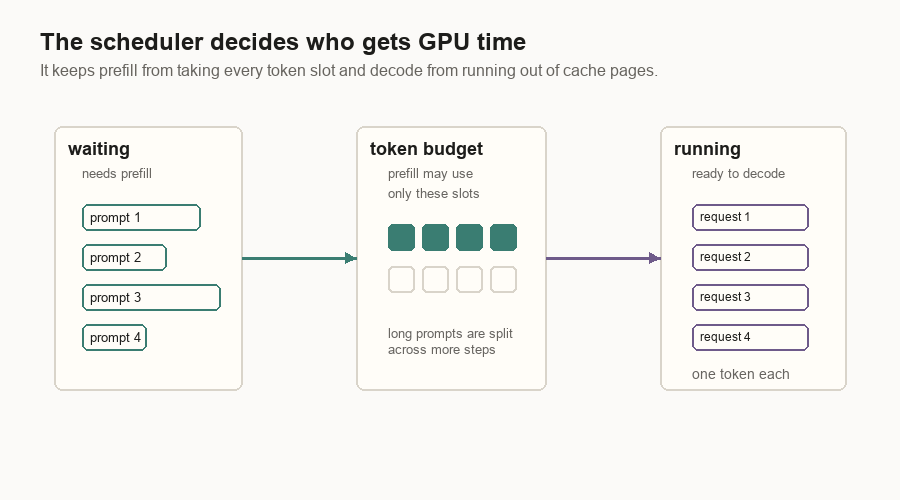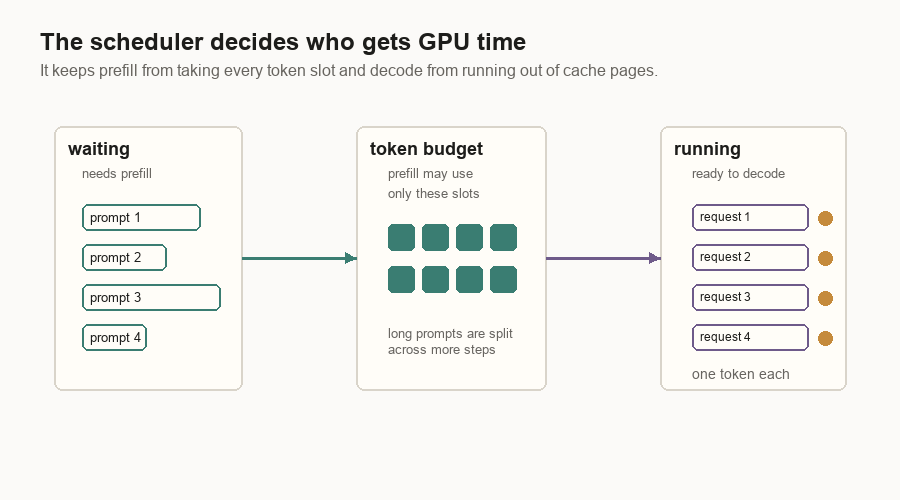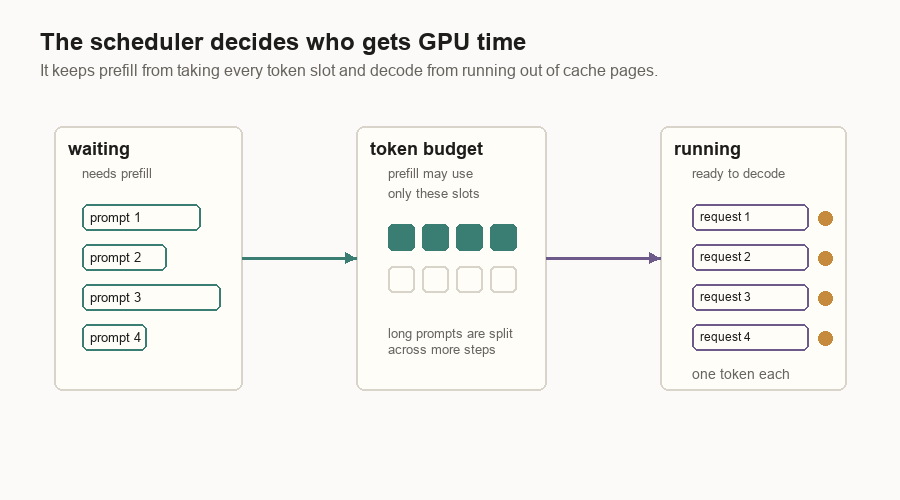
Batching is the reason one GPU can serve many users. If the model has to read a large weight matrix, it is better to use that read for many requests at once. The cost is waiting: a request may pause briefly while the scheduler forms a batch.
Blocks, Pages, And Prefix Reuse
The KV cache is too large and too dynamic to manage as one growing list per request. Inference engines split it into fixed-size pieces.
One implementation calls them blocks. Another calls them pages. The idea is the same: a request has a logical token sequence, and the server maps those token positions to physical cache pieces.
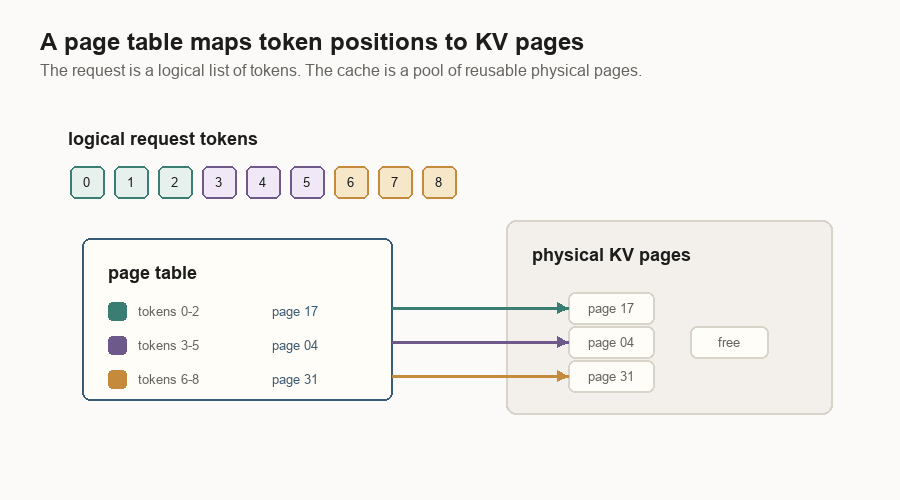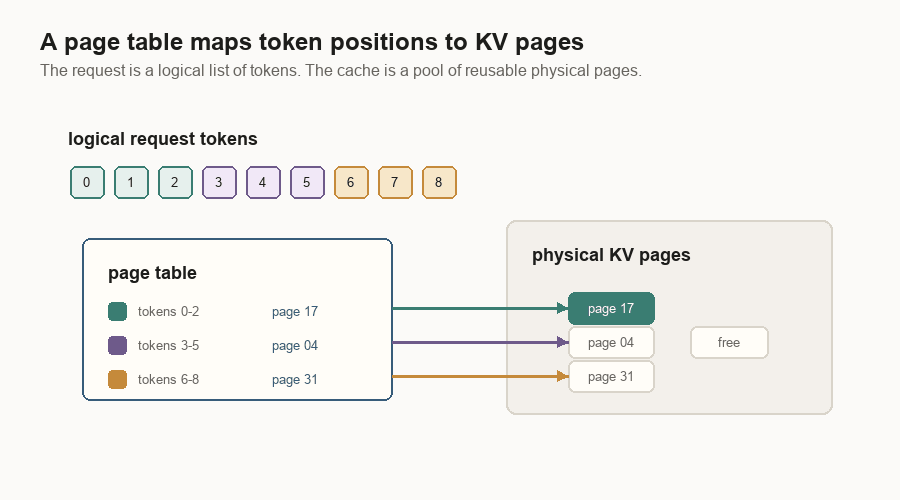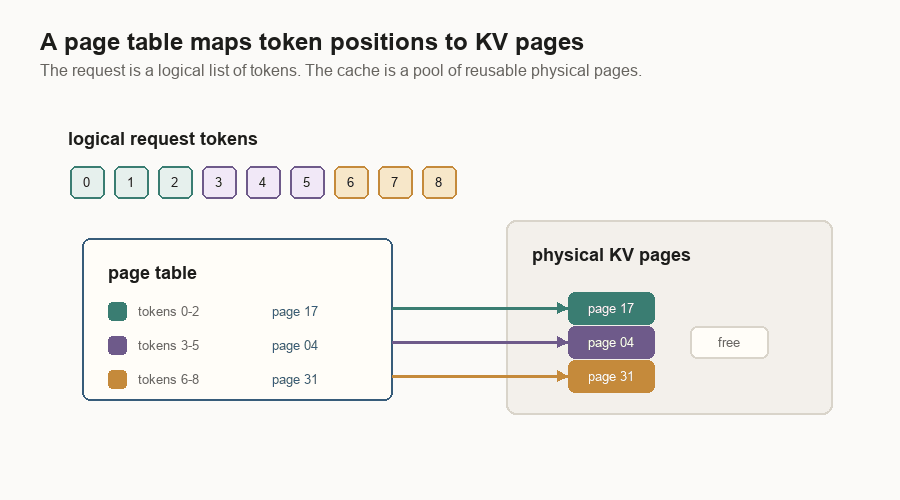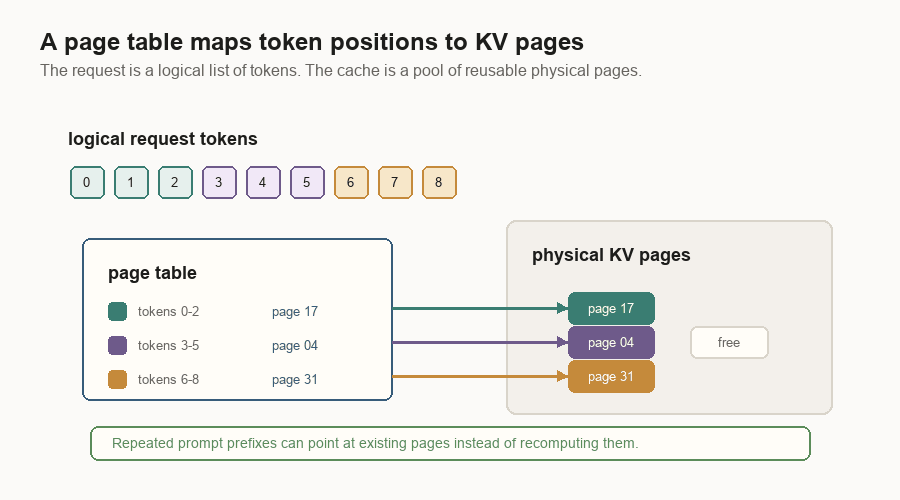
A page table is the bridge. The logical request says, “I have tokens 0 through N.” The page table says, “The KV vectors for those token ranges live in physical pages 17, 4, and 31.”
This also enables prefix caching.
Suppose two requests start with the same system prompt. The first request fills cache blocks for that prefix. The second request should not recompute those blocks. One compact engine hashes reusable full prefix blocks. A serving stack can also store shared prefixes in a radix tree. Common beginnings are shared. Divergent suffixes branch.
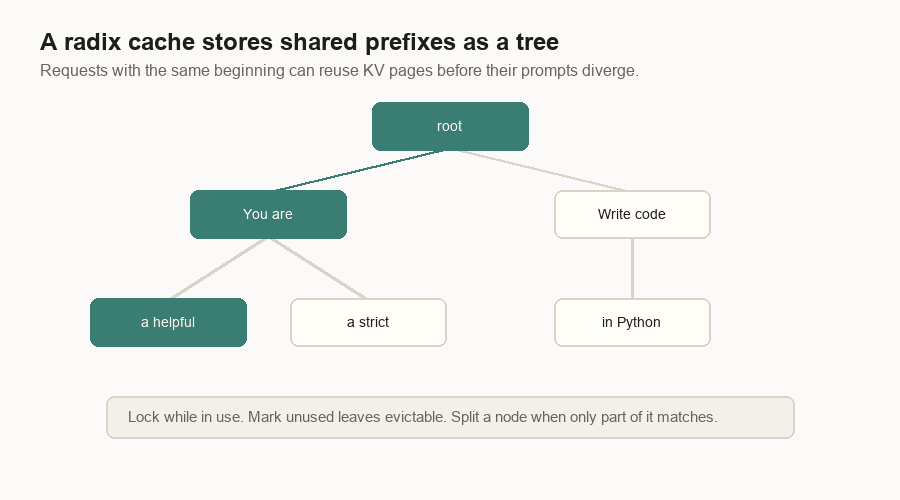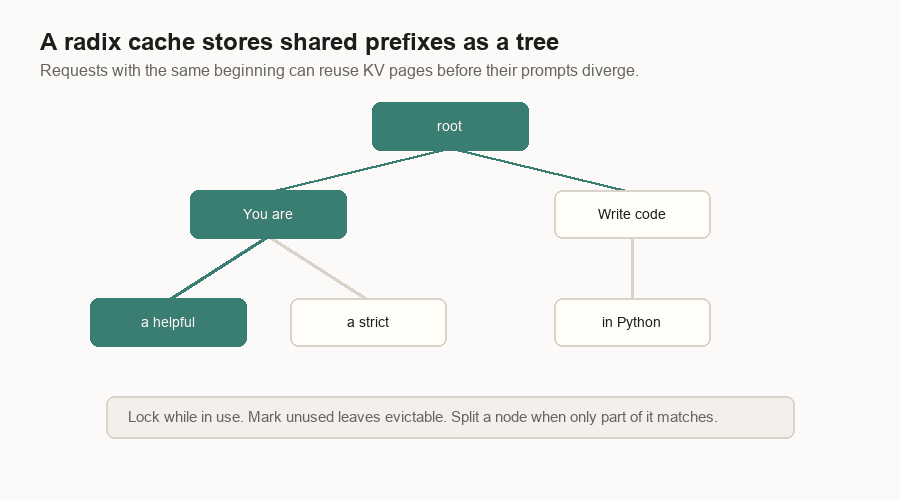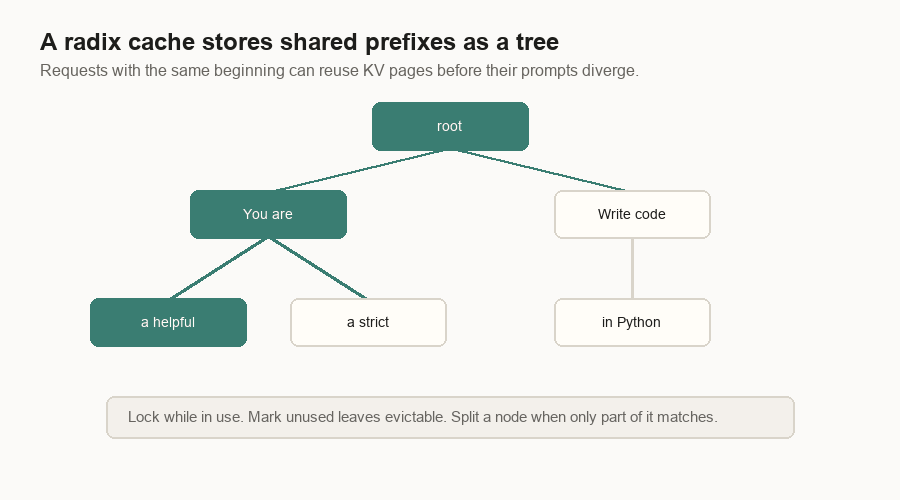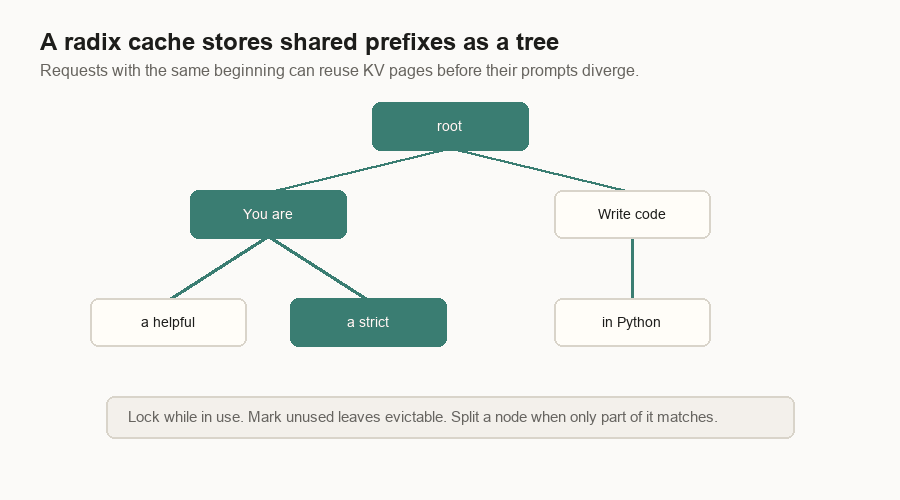
The important word is “managed.” Cached pages can be locked while live requests use them. Old unused leaves can be evicted. Prefix caching is not a vague memory of text. It is a memory-managed index over physical KV cache pages.
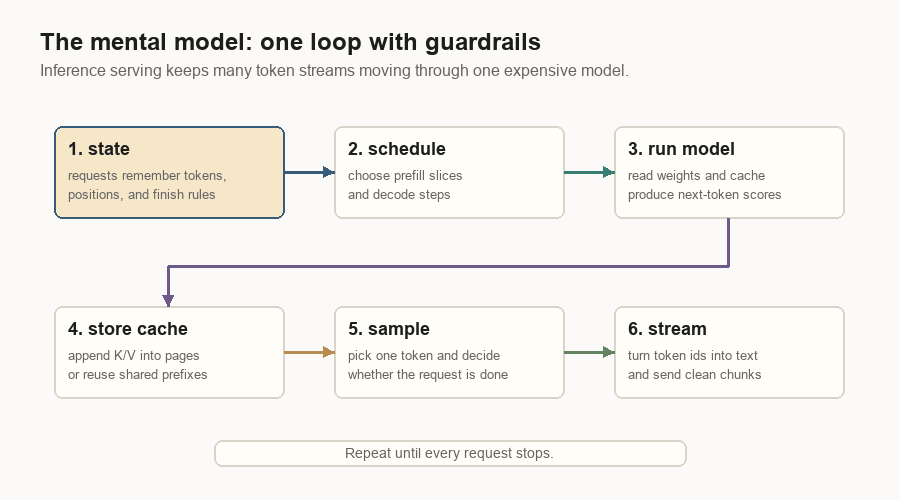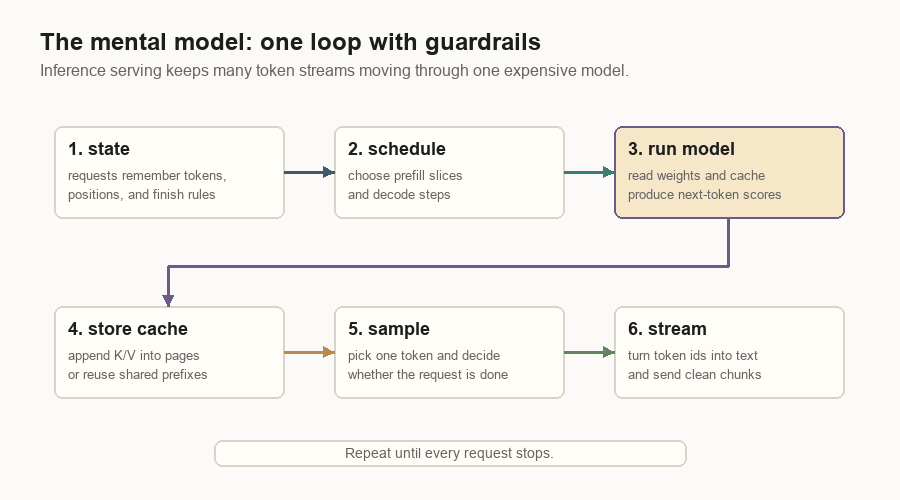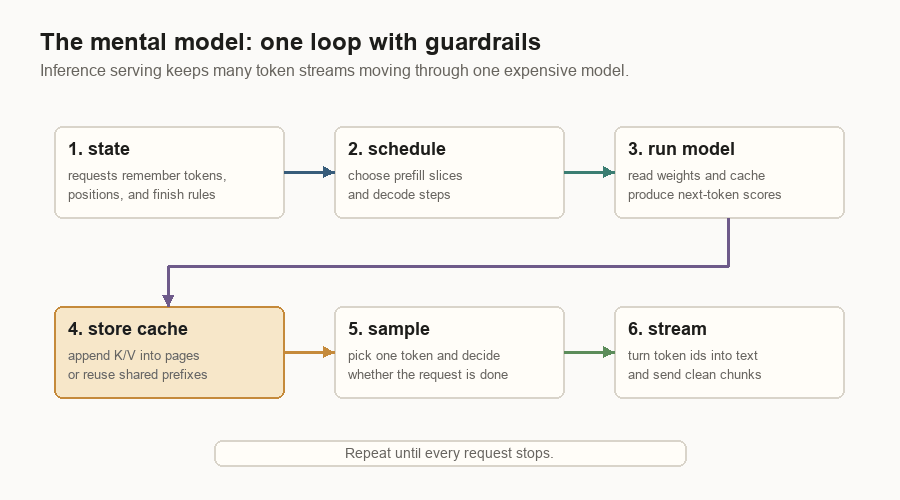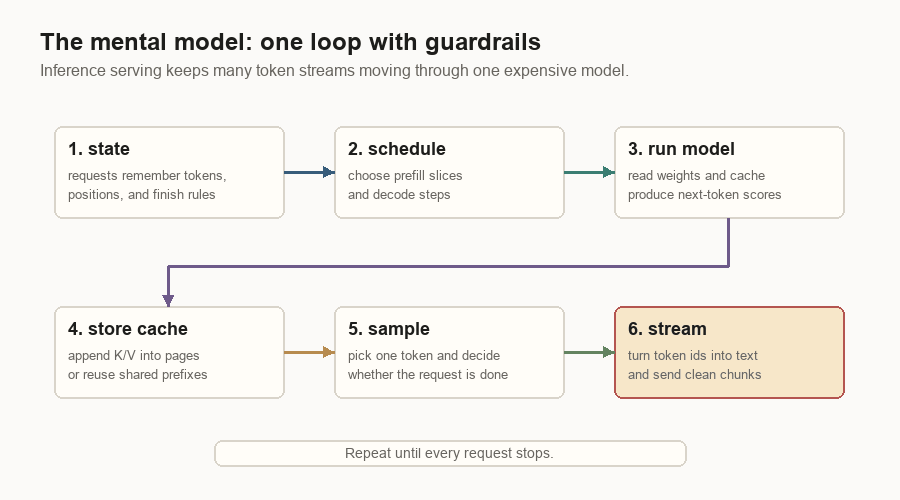
The Engine Loop
The engine loop is the smallest useful version of the inference server.
It keeps live request state, asks the scheduler what can run, packs that work into GPU-friendly tensors, runs the model, samples token ids, then updates the requests. Finished requests leave the loop. Unfinished requests come back for another decode step.
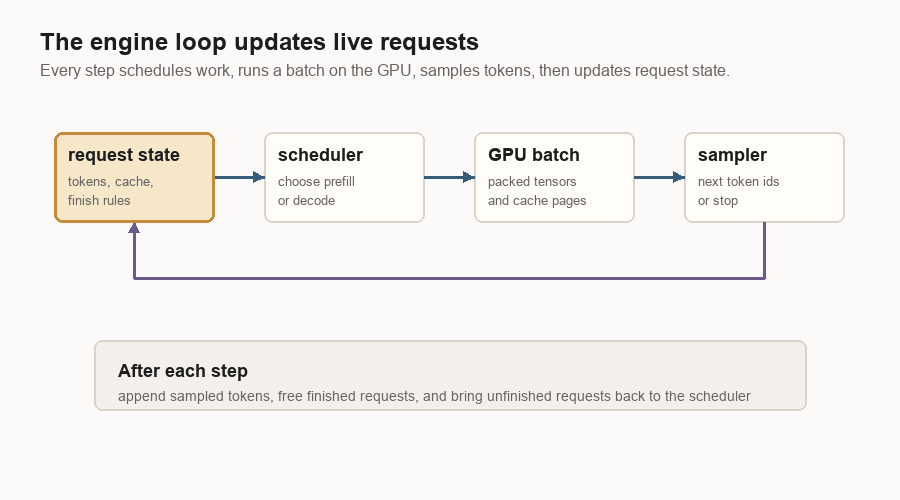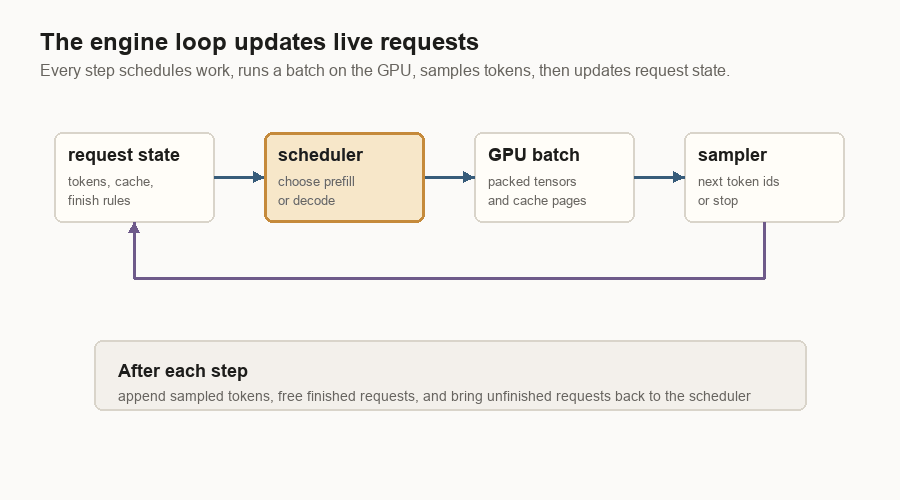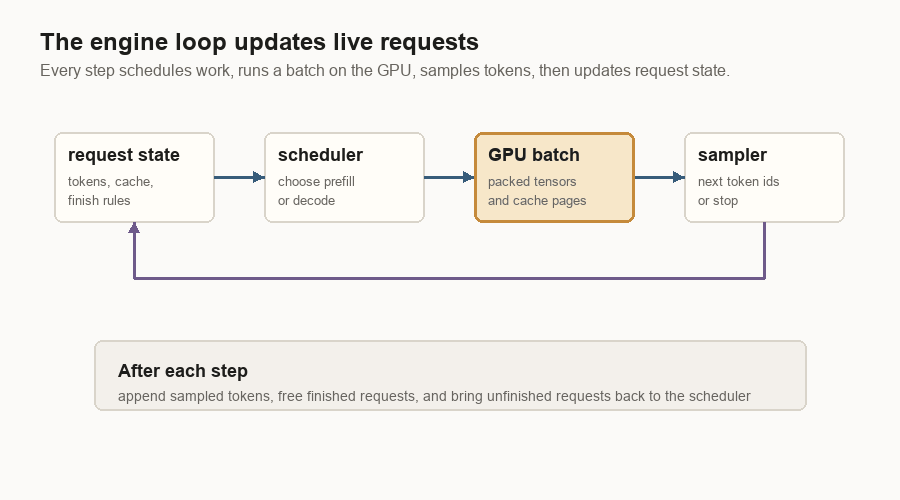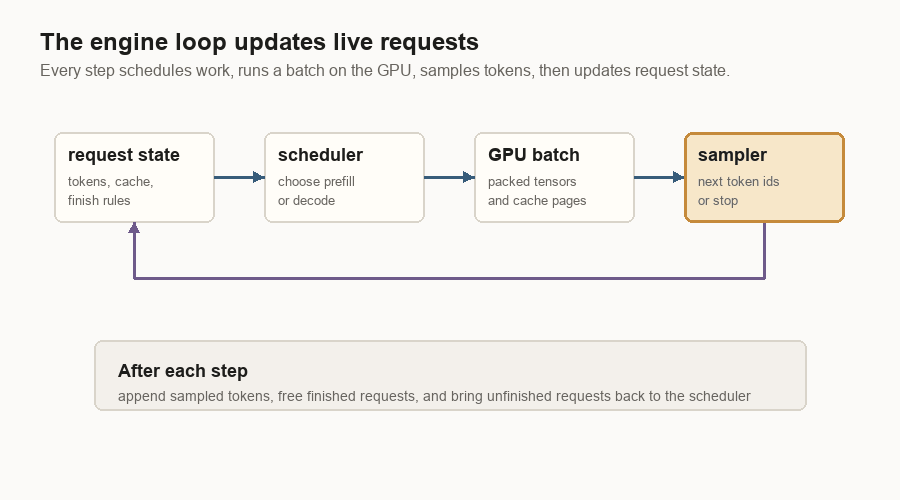
The loop has four jobs:
| Job | Plain meaning |
|---|---|
| Hold request state | Keep token ids, cache locations, sampling settings, and finish status. |
| Choose work | Decide whether this step should prefill prompts or decode running requests. |
| Prepare GPU inputs | Turn request objects into dense tensors, positions, and cache-page tables. |
| Update after sampling | Append new token ids, write new K/V, free finished requests, and repeat. |
That is the loop to understand before worrying about process boundaries.
The Tensor Metadata Boundary
GPU kernels do not consume request objects. They consume tensors.
The engine turns scheduled requests into the metadata attention kernels need:
| Metadata | Meaning |
|---|---|
| Tokens now | The token ids to run in this step. |
| Positions | The position of each token in its request. |
| Write slots | Where newly computed K/V vectors should be stored. |
| Cache pages | Which cache pages hold old K/V vectors. |
| Query lengths | How many query tokens each request contributes. |
| Context lengths | How much old context each request can attend to. |
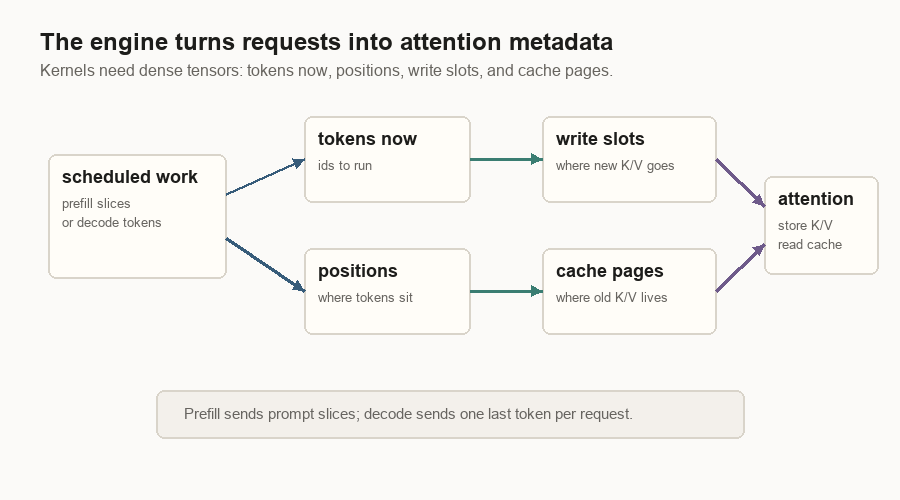
During prefill, a request may contribute many prompt tokens. During decode, it usually contributes one last token. The metadata tells the attention kernel which old cache entries belong to each request and where the new ones should go.
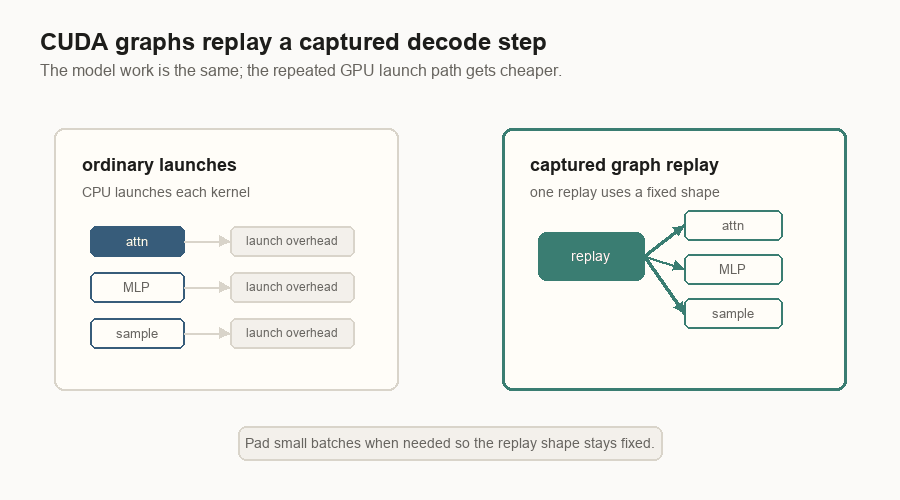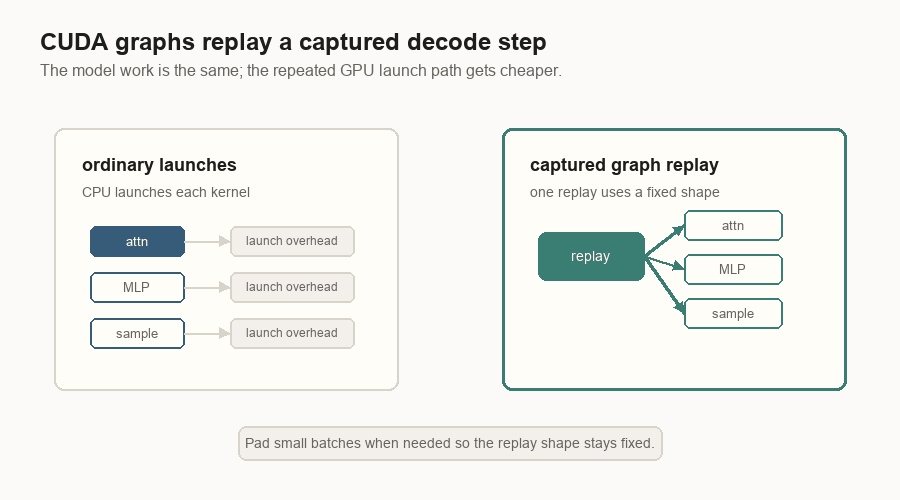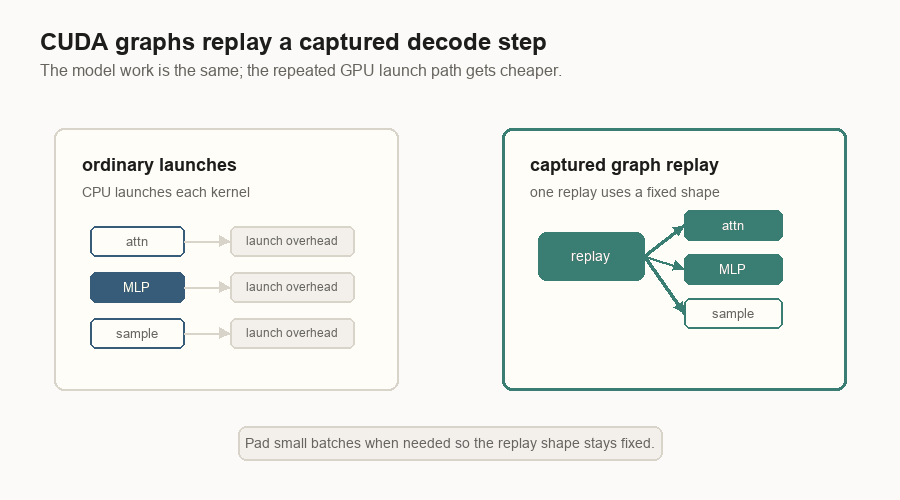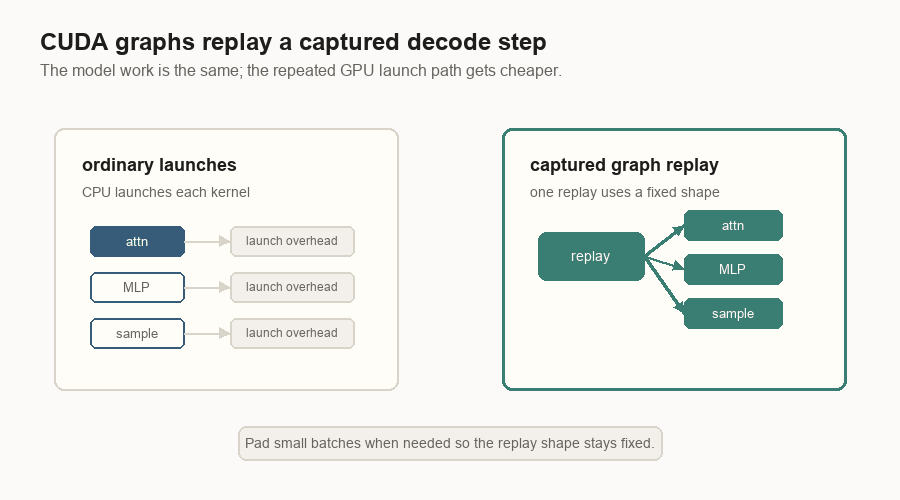
CUDA Graphs
Decode repeats the same kind of GPU work many times. The CPU overhead of launching kernels can become visible.
A CUDA graph captures a fixed pattern of GPU work and replays it later. Engines usually capture decode graphs for selected batch sizes. If a real decode batch is smaller than a captured size, the engine can pad it with dummy work so the graph shape stays stable.
This is the point: CUDA graphs do not change what the model computes. They make the repeated decode step cheaper to launch.
Tensor Parallelism
Large models may not fit on one GPU. Tensor parallelism splits model weights across GPU ranks.
Each rank computes a shard of the layer. Some layers produce different output features on each rank. Some layers produce partial sums that must be combined. The combine step is a collective operation, such as all-reduce or all-gather.
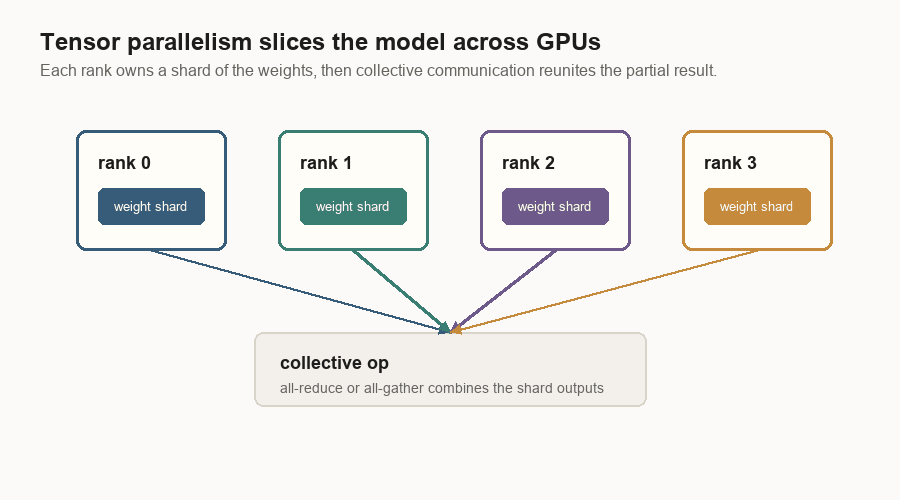
The serving consequence is simple: all ranks must run matching work for the same batch, or the distributed model stops making sense.
Serving Boundaries
Online serving wraps the engine loop in process boundaries.
The API server accepts requests and streams responses. The tokenizer turns text into ids before the GPU sees anything. The scheduler batches work and manages cache pages. The GPU engine runs the model and sampler. The detokenizer turns generated ids back into text chunks.
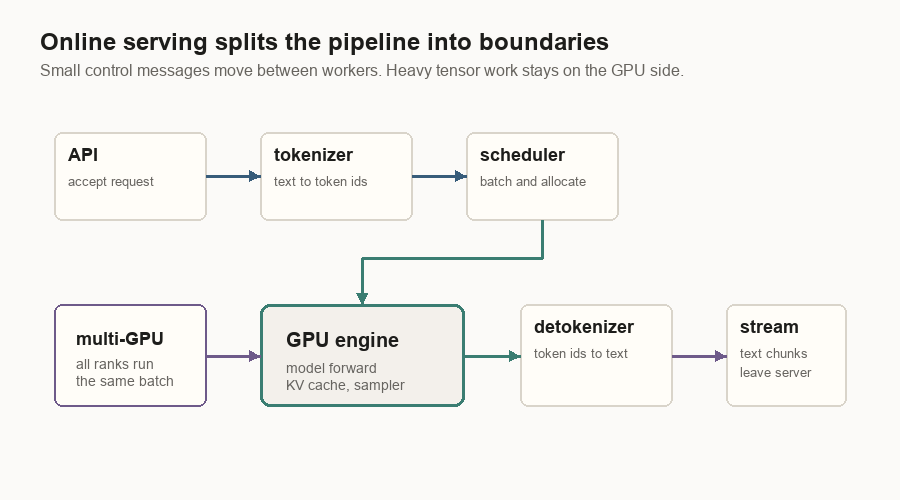
One serving implementation uses ZeroMQ (ZMQ), a messaging library, for small control messages between these workers. Heavy GPU tensor communication still happens through distributed collectives.
The request path is:
- The API server receives a generation request.
- The tokenizer worker turns text into token ids.
- The scheduler receives token ids and sampling settings.
- If the model is split across GPUs, the lead rank shares the same request with the other ranks.
- The scheduler admits the request into prefill or decode.
- The engine runs the model and sampler.
- The scheduler sends new token ids to the detokenizer.
- The detokenizer returns printable text chunks.
- The API server streams those chunks to the client.
Request State And Page Tables
The scheduler can only make good decisions if it knows where each request is.
Useful request state includes:
| State | Why it matters |
|---|---|
| Token ids | The full prompt plus generated ids so far. |
| Cached length | How many tokens already have K/V entries. |
| Staged length | How many tokens are currently staged for GPU work. |
| Maximum length | Where generation must stop. |
| Page-table row | Where this request’s cache-page pointers live. |
| Prefix-cache handle | Which shared prefix, if any, the request is reusing. |
Cached length and staged length explain most prefill behavior. During prefill, the request is trying to make cached length catch up to the known prompt. During decode, the request usually extends by one token.
A token pool stores active token ids. A page table stores physical cache locations for each request position. The page table is the seating chart for cache memory: a request does not own one neat continuous slab of GPU memory. It owns table entries that point to pages.
Chunked Prefill
A long prompt can be too large to prefill all at once. Chunked prefill splits that prompt into pieces.
A scheduler can enforce a maximum number of prompt tokens to extend in one step. If an uncached prompt is longer than the current budget, the scheduler admits only the next chunk. That request cannot decode yet. It comes back for more prefill until the prompt is caught up.

This is a serving feature. It keeps one long-context request from making the system less usable for everyone else.
Attention Backends
An attention backend is the implementation of attention used by the engine. It may be FlashAttention, FlashInfer, TensorRT-LLM FMHA, or a hybrid. A hybrid can use one backend for prefill and another for decode.
That choice matters because prefill and decode have different shapes. Prefill may process long variable-length prompt chunks. Decode often processes one new token per request while reading a large cached context. A kernel that is best for one shape may not be best for the other.
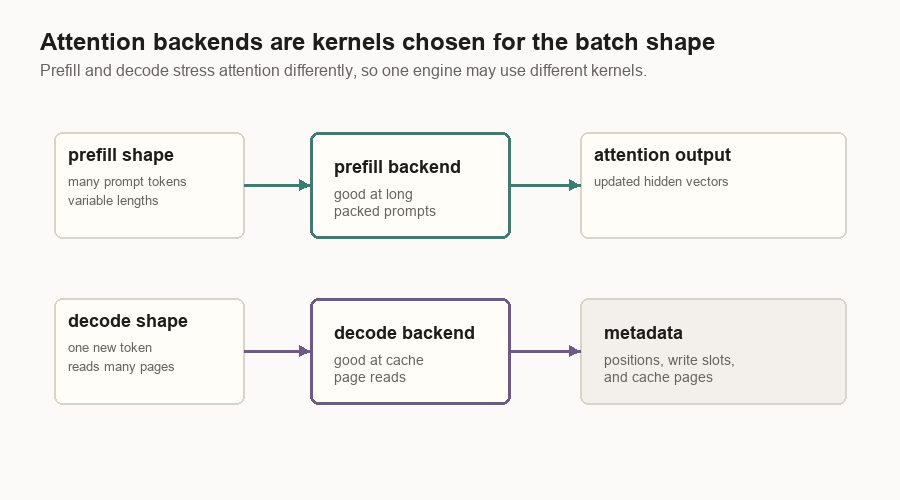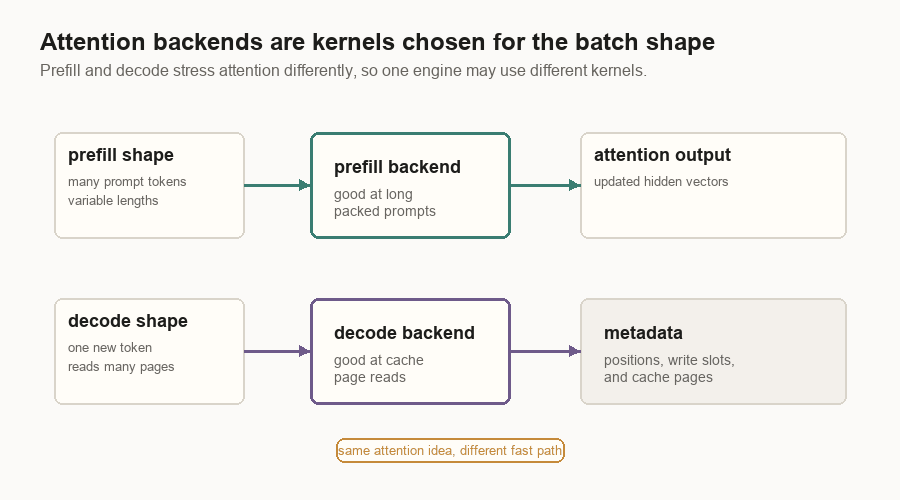
The attention path is:
- The scheduler forms a batch.
- The cache manager allocates pages.
- The attention backend prepares metadata.
- The attention layer stores new K/V vectors.
- The backend runs the attention kernel over the right cache pages.
That is what people mean when they say serving performance depends on the attention backend.
Overlap Scheduling
CPU work can leave the GPU waiting. The scheduler has to receive messages, allocate pages, prepare metadata, handle sampled tokens, free finished requests, and send replies.
Overlap scheduling rearranges that work. While the GPU runs the current batch, the CPU prepares the next batch and processes the previous result.
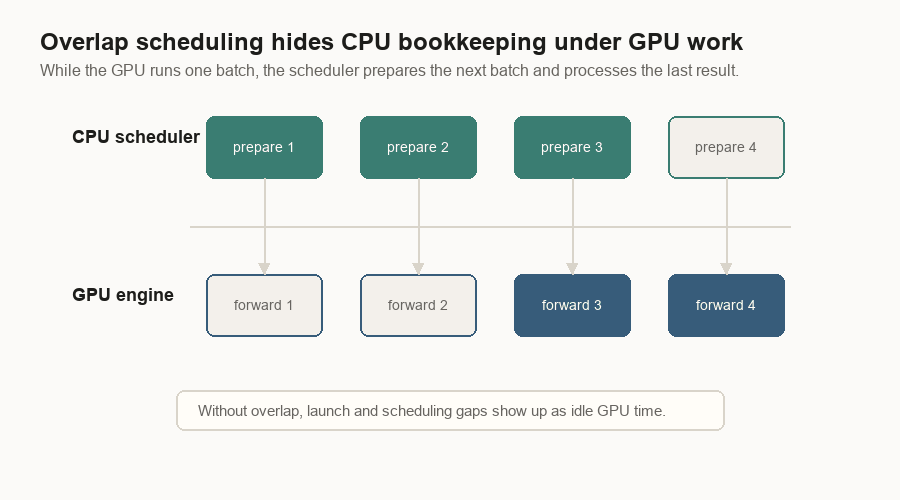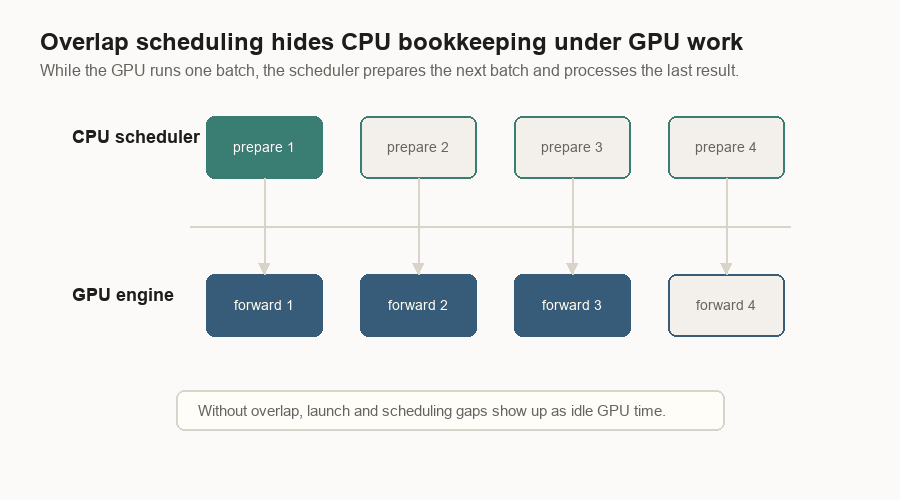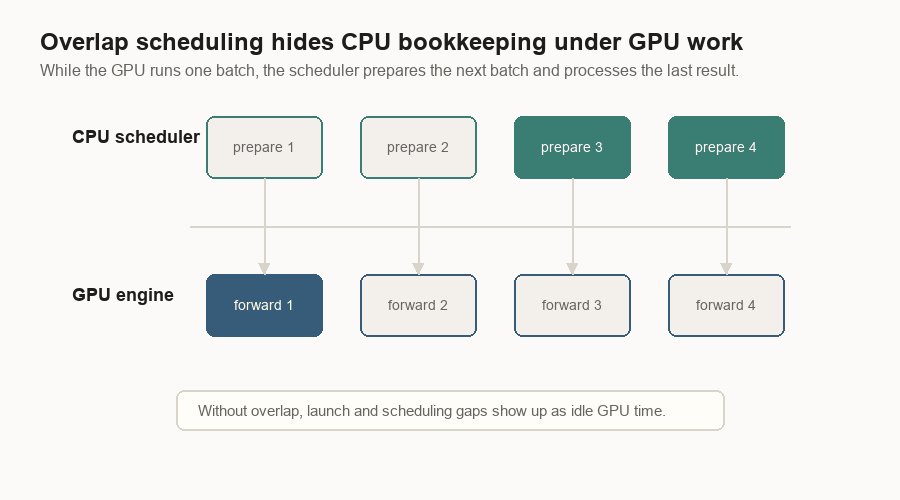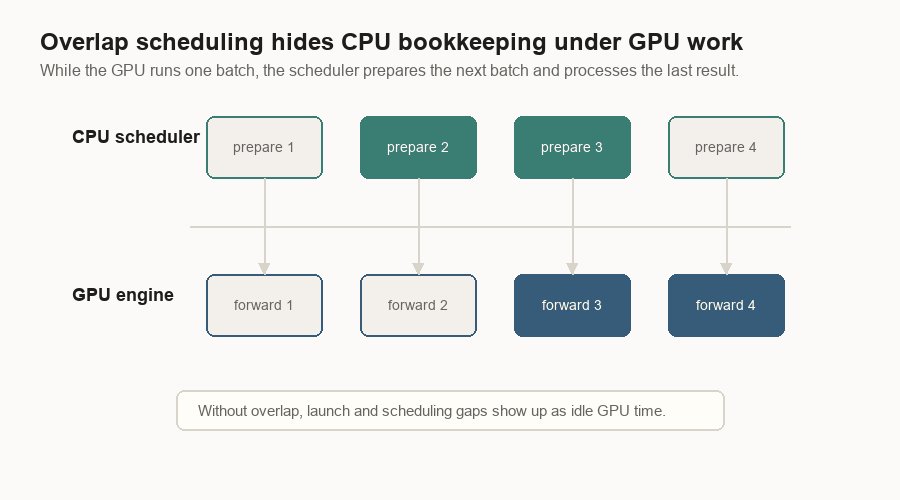
The normal serving loop is easy to read:
- Receive messages.
- Schedule a batch.
- Run the batch.
- Process the result.
The overlap loop carries an in-flight result between iterations:
- Receive messages.
- Schedule and start the next batch.
- Process the previous result.
- Carry the current result into the next loop.
The goal is less idle GPU time.
Detokenization And Streaming
The model emits token ids. The client wants text.
The detokenizer keeps decode state for each request. It decodes new ids, avoids sending broken replacement characters, and tries not to flush half a word when it can wait for printable text.
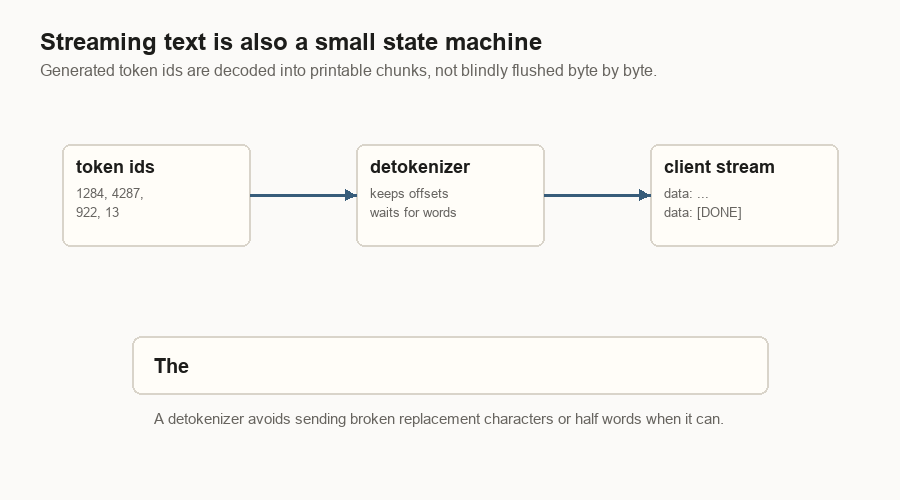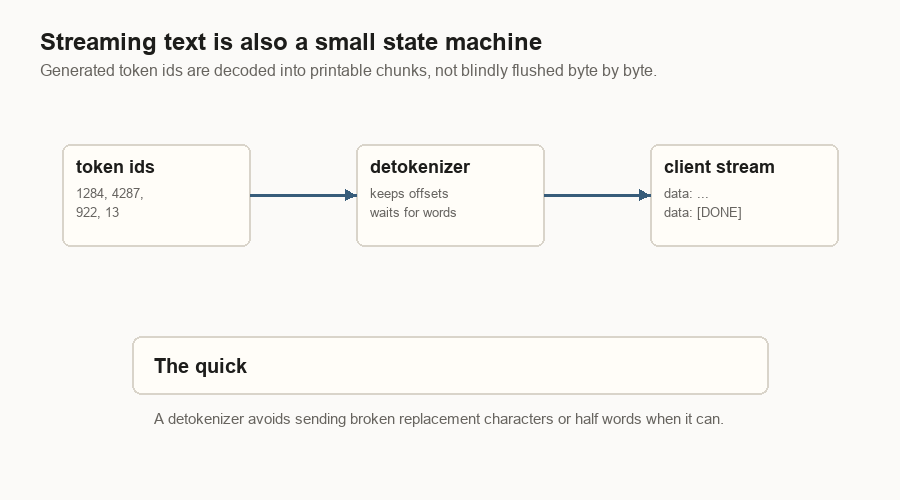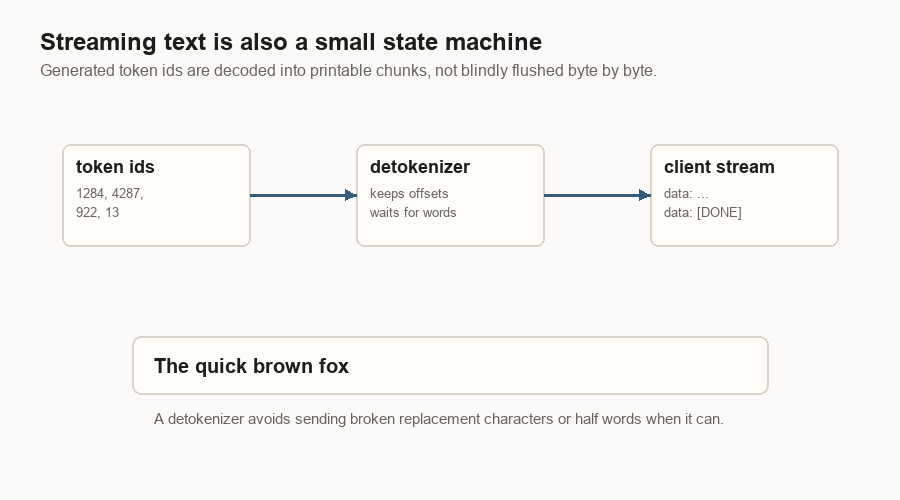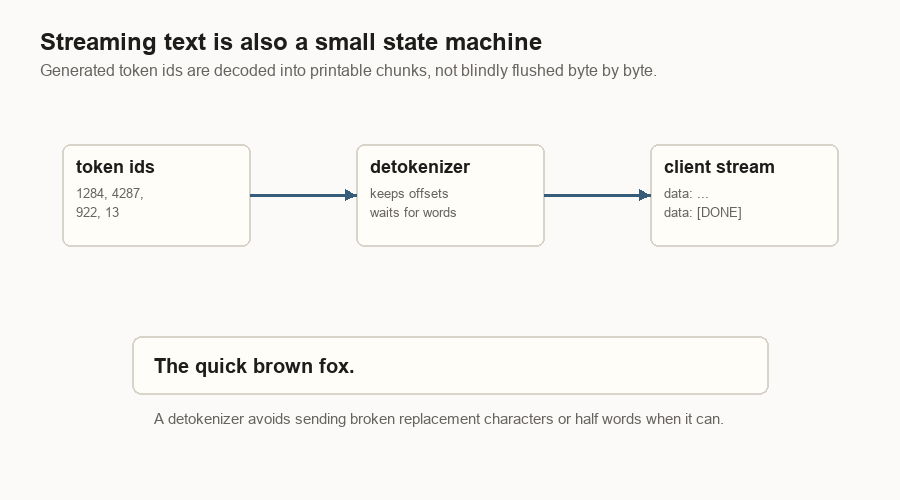
That last boundary matters. A good streaming server has to be fast and send chunks that clients can display cleanly.
The Mental Model
The model predicts the next token. The inference server makes that prediction usable for many live requests at once.
The whole system follows from a few constraints:
| Constraint | Consequence |
|---|---|
| Future tokens depend on past tokens. | Decode is a repeated one-token loop. |
| Attention needs old keys and values. | The KV cache is central. |
| GPU memory is finite. | Blocks, pages, eviction, and preemption matter. |
| Prompts repeat. | Prefix caching saves prefill work. |
| CPU overhead can stall the GPU. | CUDA graphs and overlap scheduling matter. |
| Models outgrow one GPU. | Tensor parallelism adds collectives. |
| Users expect text, not token ids. | Detokenization and streaming state matter. |
Everything else in the serving stack is an answer to those constraints.